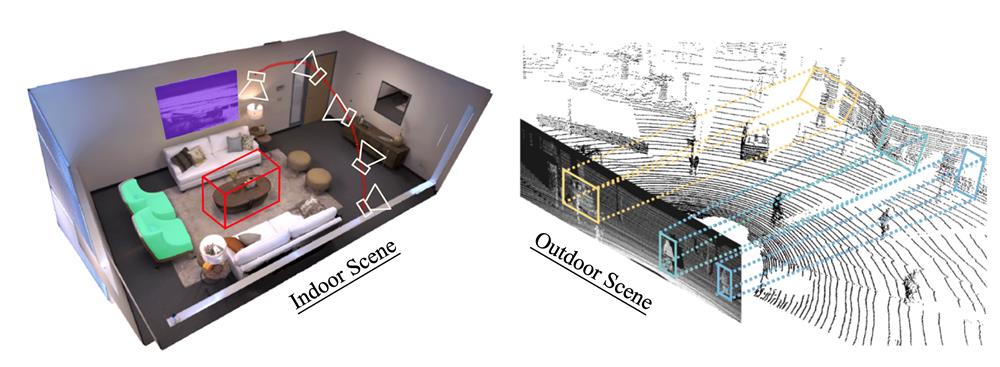
We aim to explore the possibilities of computer perception and understanding of 3D scenes. Our basic research involves specifying the position and movement patterns of subjects in the environment from sensor inputs and forming robust 3D representations of the environment and the objects within it, with the ultimate goal of providing a perceptual algorithmic basis for the vision of computers acting freely in the real world. Specifically, we aim to combine classical geometric methods in computer vision with learning-based semantic understanding to achieve this goal efficiently and accurately.
On the other hand, robust 3D representation of the environment and the objects within it involves 3D reconstruction of the scene and 3D detection of the objects. To achieve this, we expect to combine computer vision and computer graphics and efficiently extract key information from multimodal sensors to build accurate and comprehensive 3D representations of the scene and objects in terms of practical requirements.
Selected Papers
 |
 |
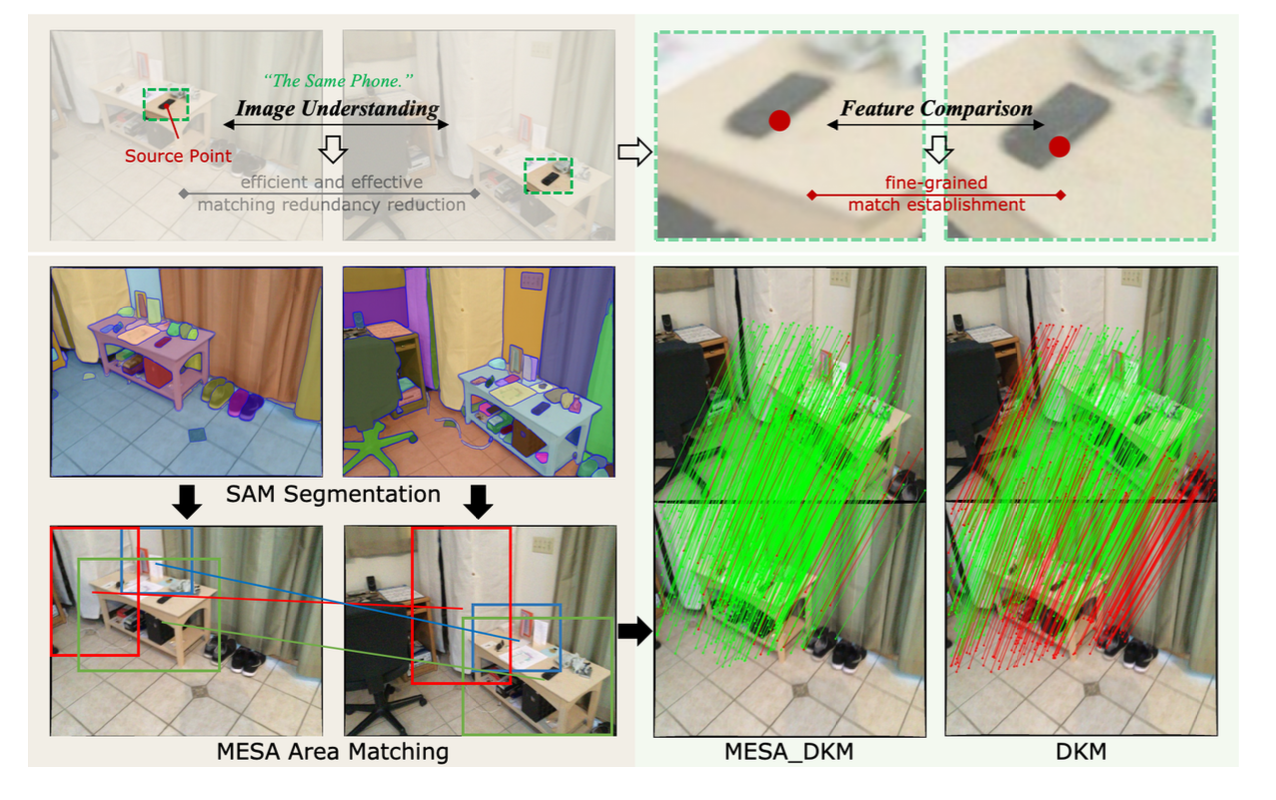
MESA: Effective Matching Redundancy Reduction by Semantic Area Segmentation |
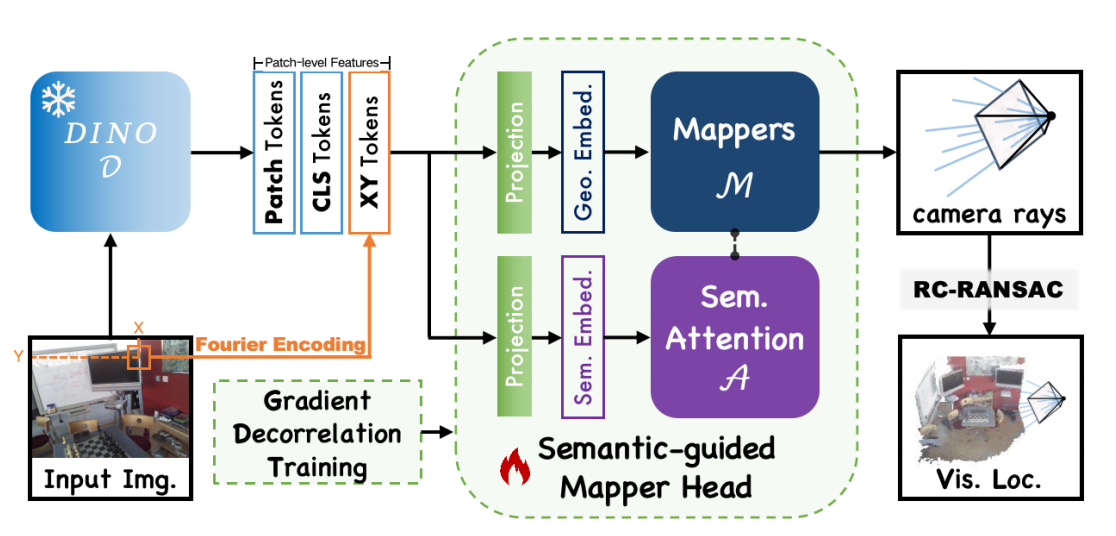 |
Semantic-guided Camera Ray Regression for Visual Localization |
 |
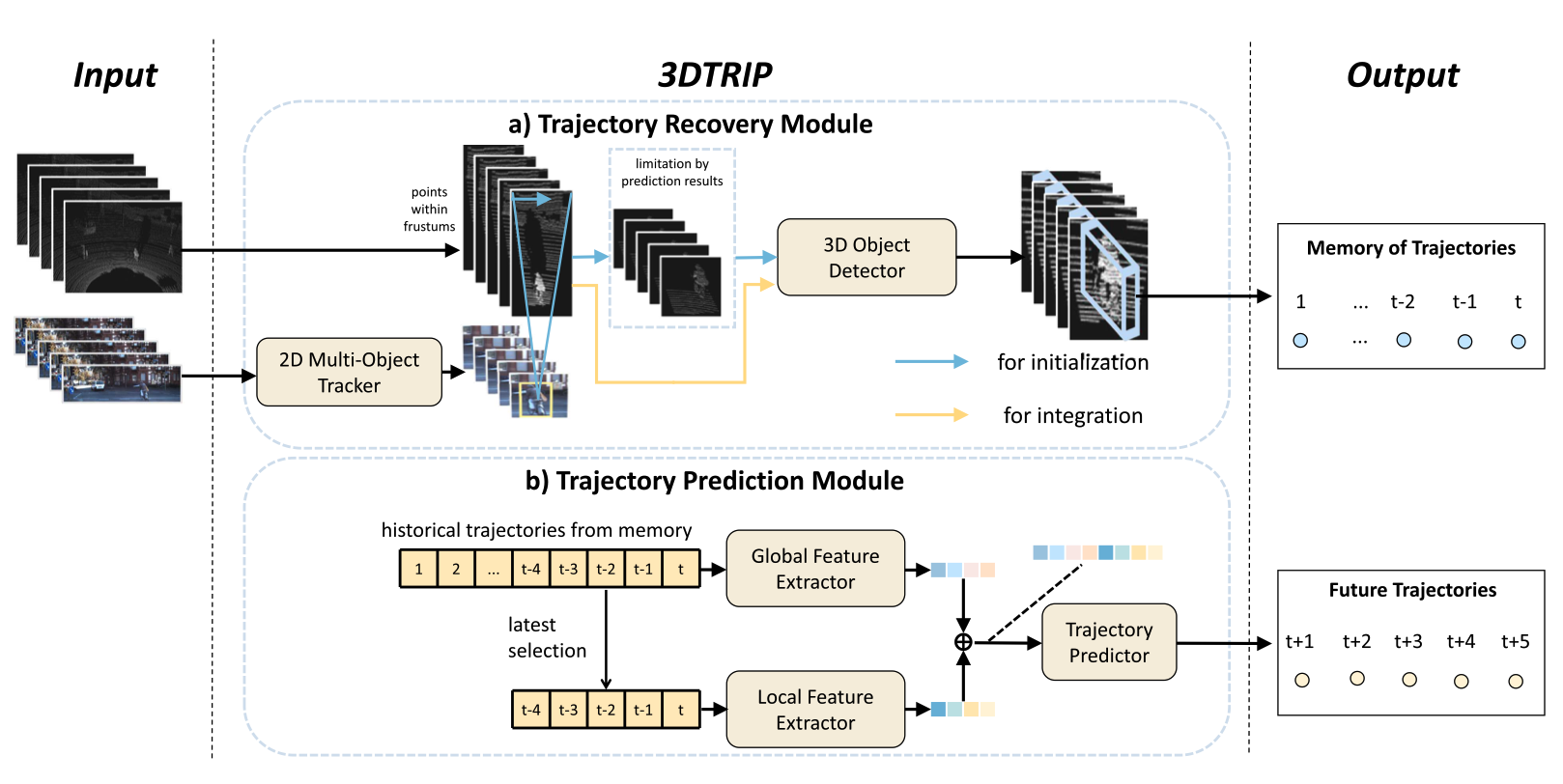 |
3DTRIP: A General Framework for 3D Trajectory Recovery Integrated With Prediction IEEE Robotics and Automation Letters 2023 [BibTex] |
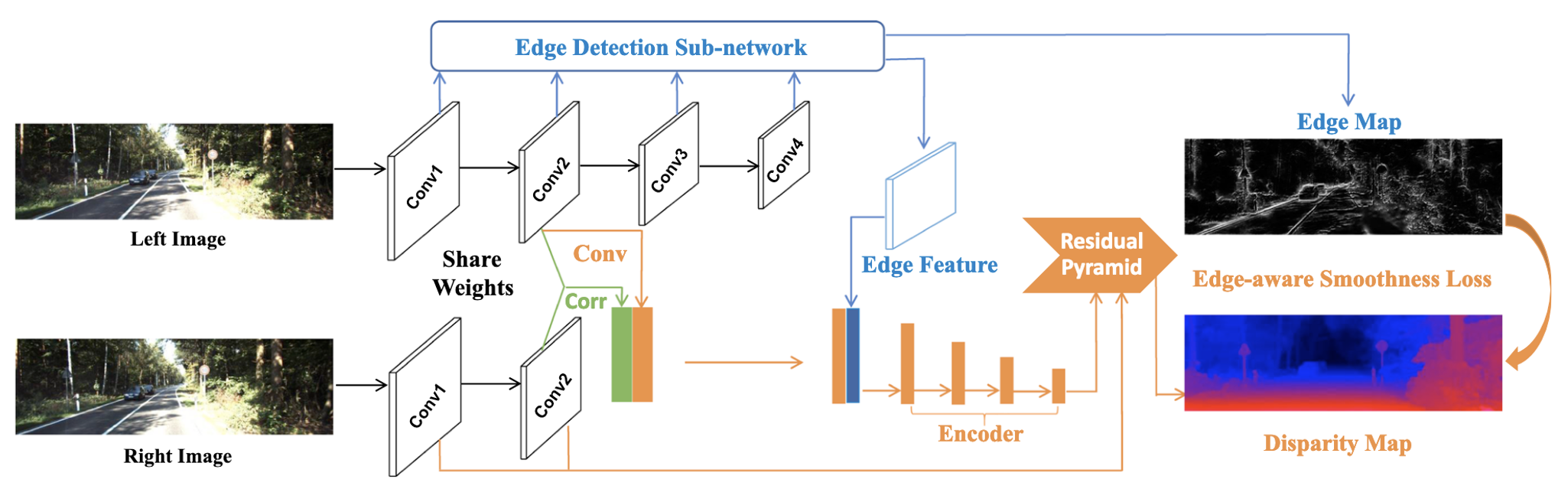 |
EdgeStereo: An Effective Multi-task Learning Network for Stereo Matching and Edge Detection IJCV 2020 [BibTex] |
Copyright © 2024 Computer Vision Laboratory
Address:上海市闵行区东川路800号上海交通大学电院群楼
Zip:200240
备案许可证:沪ICP备05003369