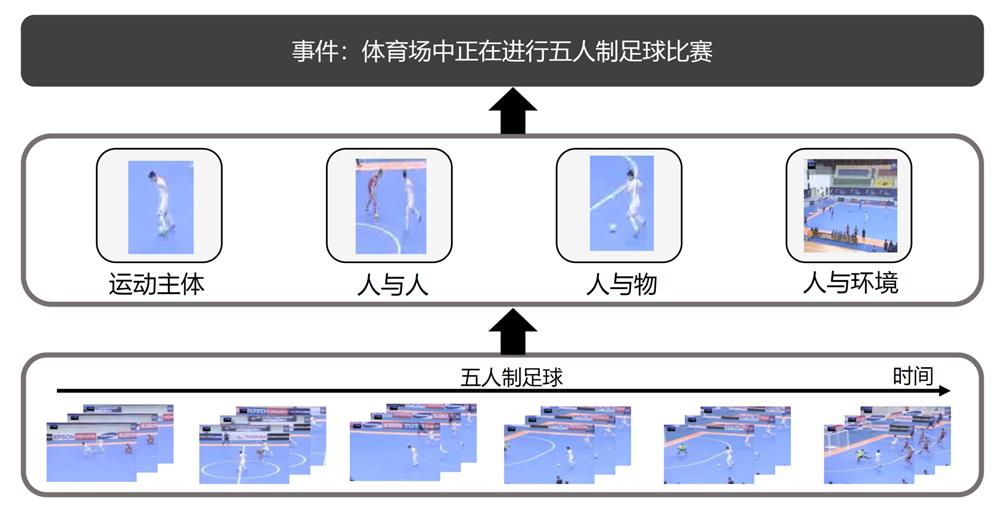
Video action understanding uses algorithms to analyze the relationship between moving subjects, people and people, people and objects, and people and environment in the video and understands the actions and behaviors of people in the video. Additionally, video action understanding detects the events by combining the temporal information of the video. We mainly focus on the four sub-tasks: atomic action segmentation, video action recognition, temporal action detection and spatio-temporal action detection.
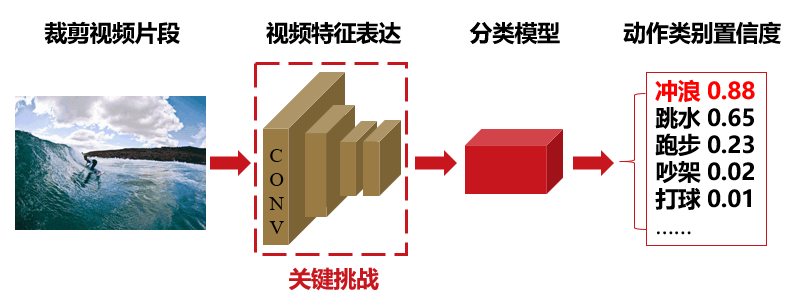
1. Video action recognition is a basic task in video action understanding, which can serve downstream temporal action detection and spatiotemporal action detection tasks. Video action recognition is to identify the action category in a trimmed video and give the confidence of the action category. Its core is video feature expression, which usually uses optical flow frames and RGB frames to extract motion information and appearance information in videos. We are committed to extracting video features more efficiently and effectively. We seek to decouple video features at the spatial and temporal levels at the video level to improve the interpretability of video features. At the same time, we aim at the huge amount of 3D convolution parameters. The structure decomposition of the convolution kernel is used to reduce the amount of model parameters and improve the calculation efficiency of the model.
2. Temporal action detection is to locate the boundary of the action in untrimmed videos, and give the corresponding action category of the action segment. Temporal action detection has important value in video editing, video recommendation, and intelligent monitoring. We strive to build more accurate descriptions of action boundaries and generate high-quality action nomination segments. To propose more accurate action segments, we propose a more flexible temporal action detection framework. In addition, for the ambiguity of the action boundary, the boundary feature is learned in the video feature expression to highlight the difference between the action and background of the video.

3. Spatio-Temporal Action Detection is an important research direction in the field of video behavior understanding. Its goal is to locate and identify interesting actions in videos simultaneously in time and space, which is of great significance for understanding the spatiotemporal evolution mode of actions in videos. Compared with simply detecting the start and end time of an action in time, the detection of the spatial position of the action subject on each frame provides a broader practical prospect for the practical application of this research direction. On the basis of the existing frame-level and snippet-level spatio-temporal action detection methods, we focus on improving the multi-task feature learning ability of the model and improving the effect of action modeling. At the same time, we also explore the semi-supervision of spatio-temporal action detection in data-scarce scenarios.
4. Atomic action segmentation is an important step in understanding the temporal relationship between complex actions. Its goal is to divide a complete action into several atomic actions in time without supervision. These atomic actions constitute a compact representation of the original action in time and a complete description of semantics. Compared with the rough division of actions under an event in temporal action segmentation, unsupervised atomic actions have a more fine-grained division of the original action, which will improve the ability of action modeling in action recognition and action detection. Based on deep learning, we foucs on improving the feature representation ability in unsupervised atomic action segmentation and the ability to model the temporal relationship between atomic actions. In addition, we also focus on combining atomic action segmentation with subsequent video understanding tasks.

Selected Papers
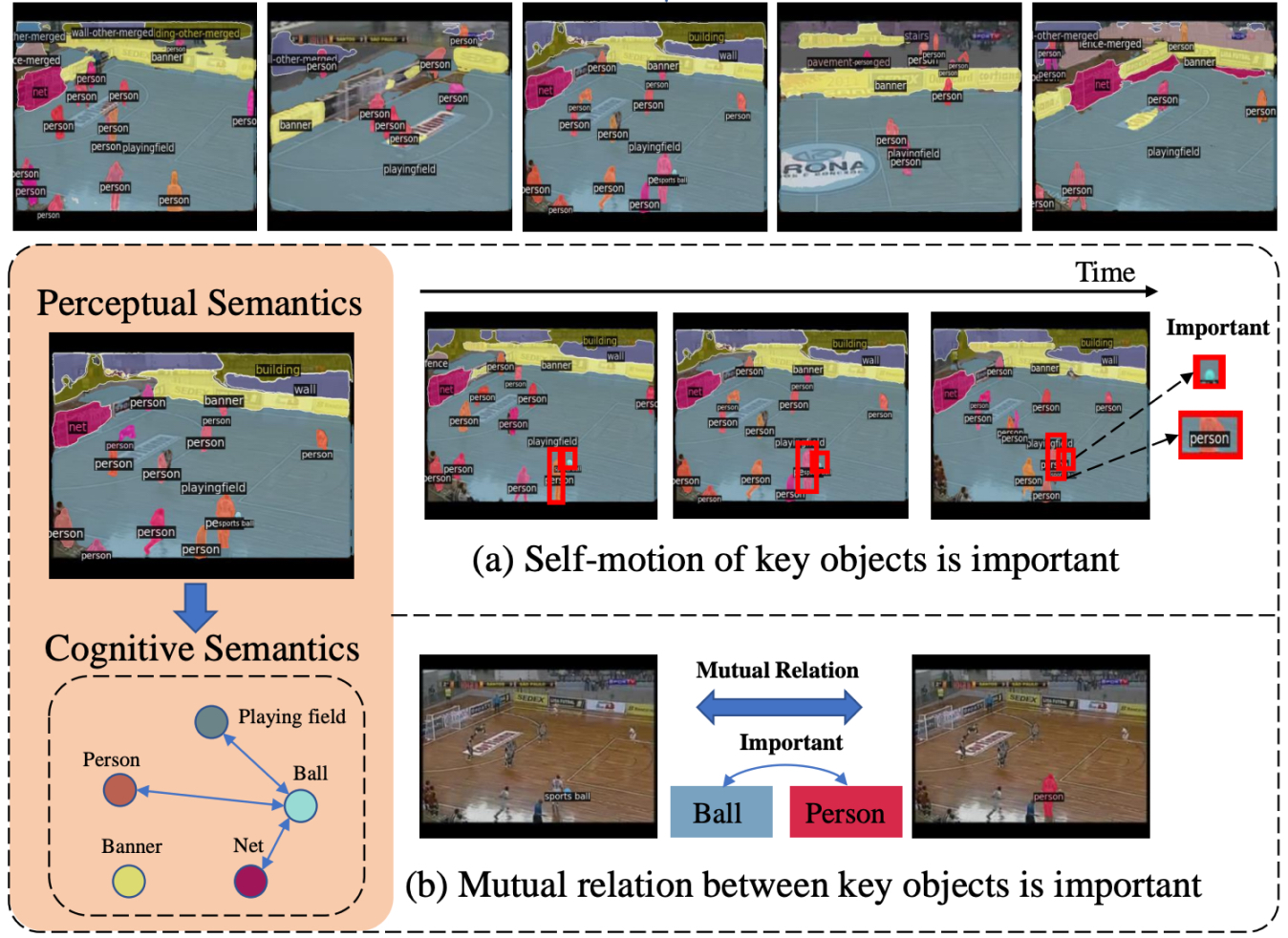 |
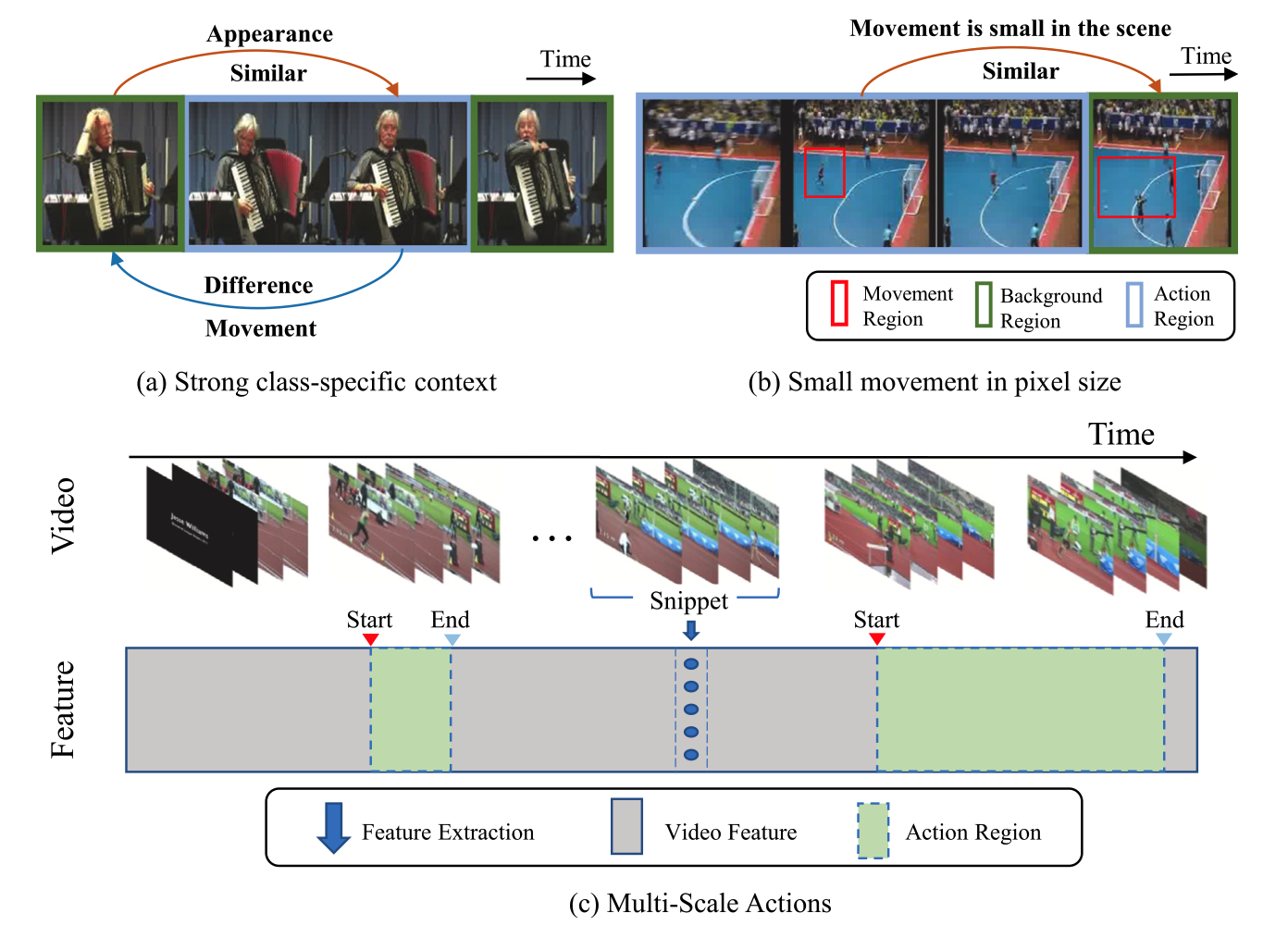 |
Pattern Recognition 2024 [BibTex] |
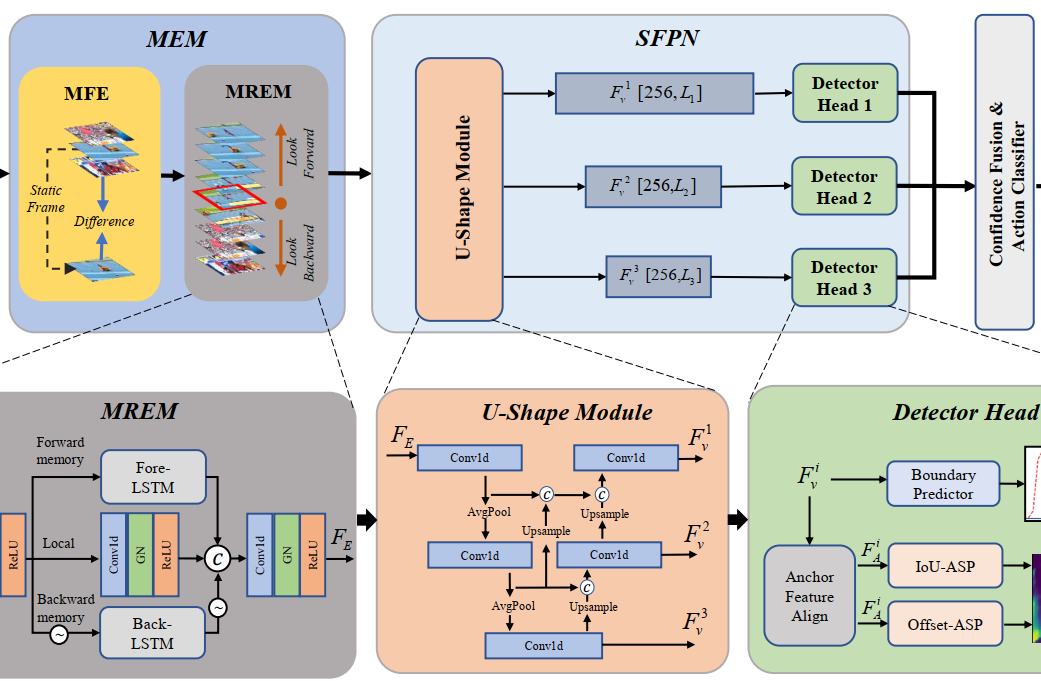 |
Movement Enhancement toward Multi-Scale Video Feature Representation for Temporal Action Detection |
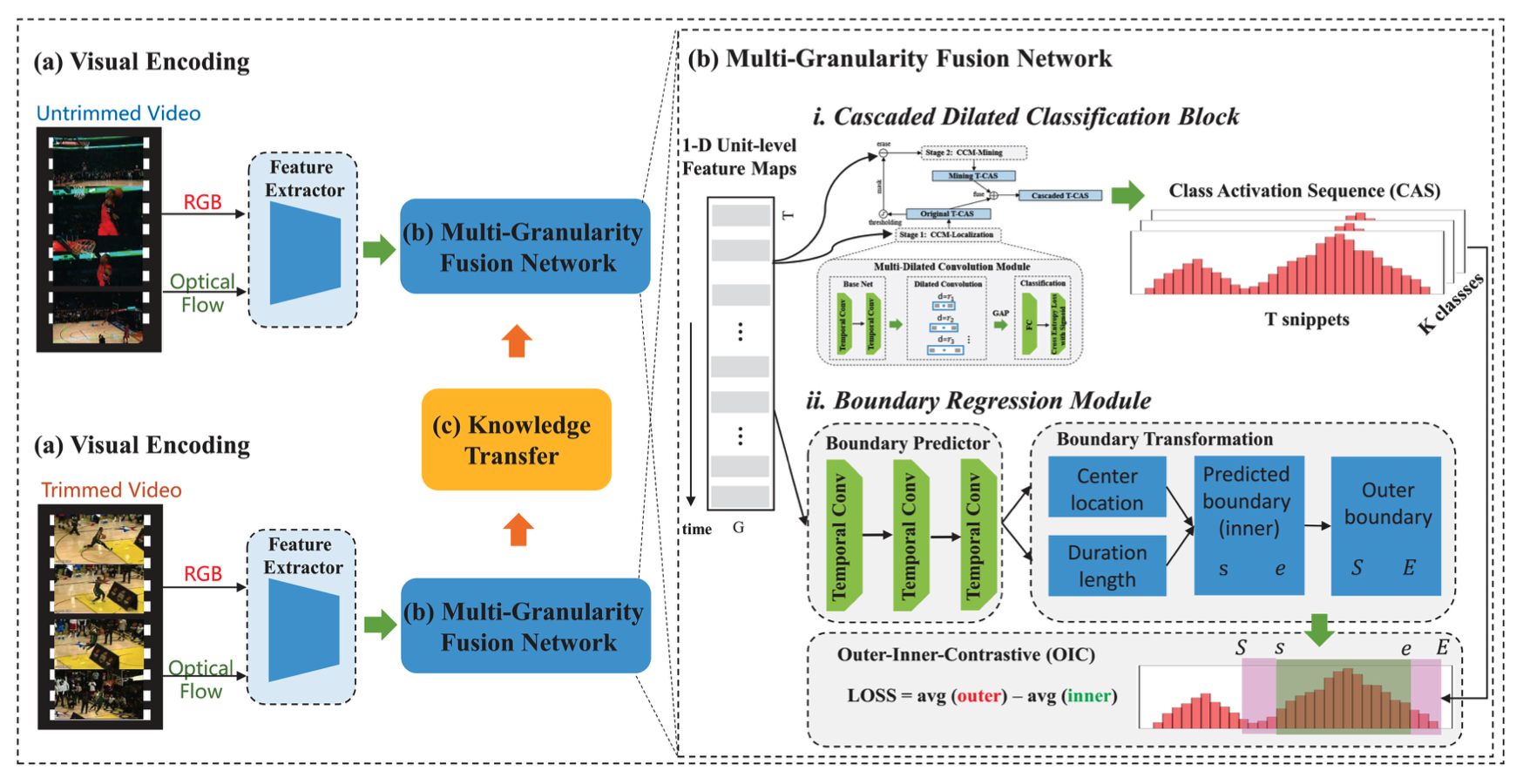 |
IEEE Transactions on Multimedia 2021 [BibTex] |
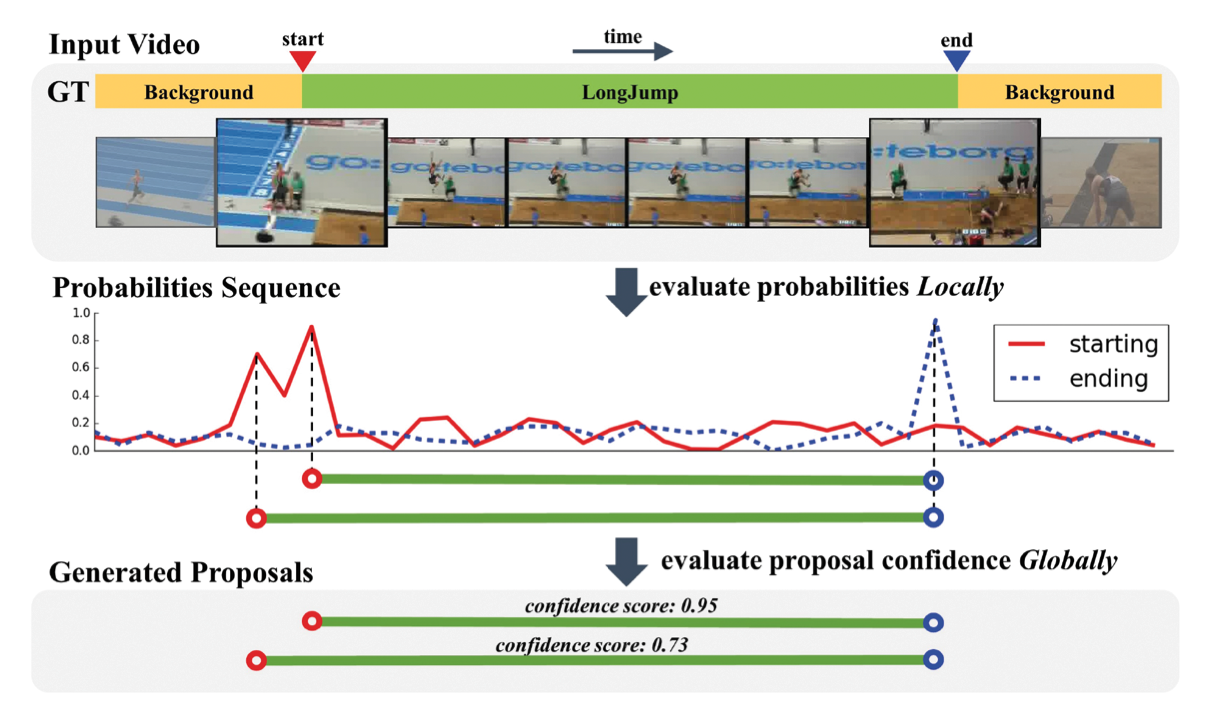 |
BSN: Boundary Sensitive Network for Temporal Action Proposal Generation ECCV 2018 [BibTex] |
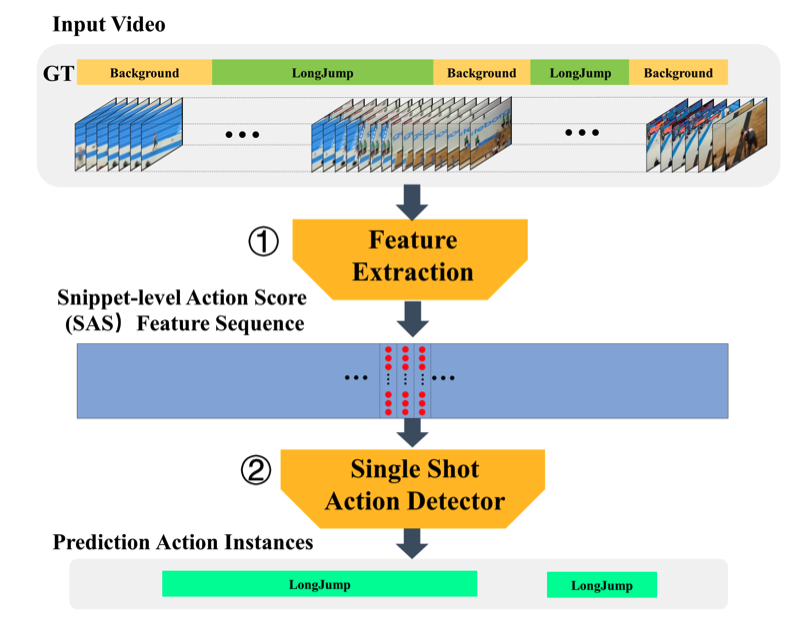 |
Single Shot Temporal Action Detection ACM MM 2017 [BibTex] |
Copyright © 2024 Computer Vision Laboratory
Address:上海市闵行区东川路800号上海交通大学电院群楼
Zip:200240
备案许可证:沪ICP备05003369