Constructing Semantical Structure by Segmentation Integrated Video Embedding for Temporal Action Detection
IEEE TCSVT 2025
Abstract
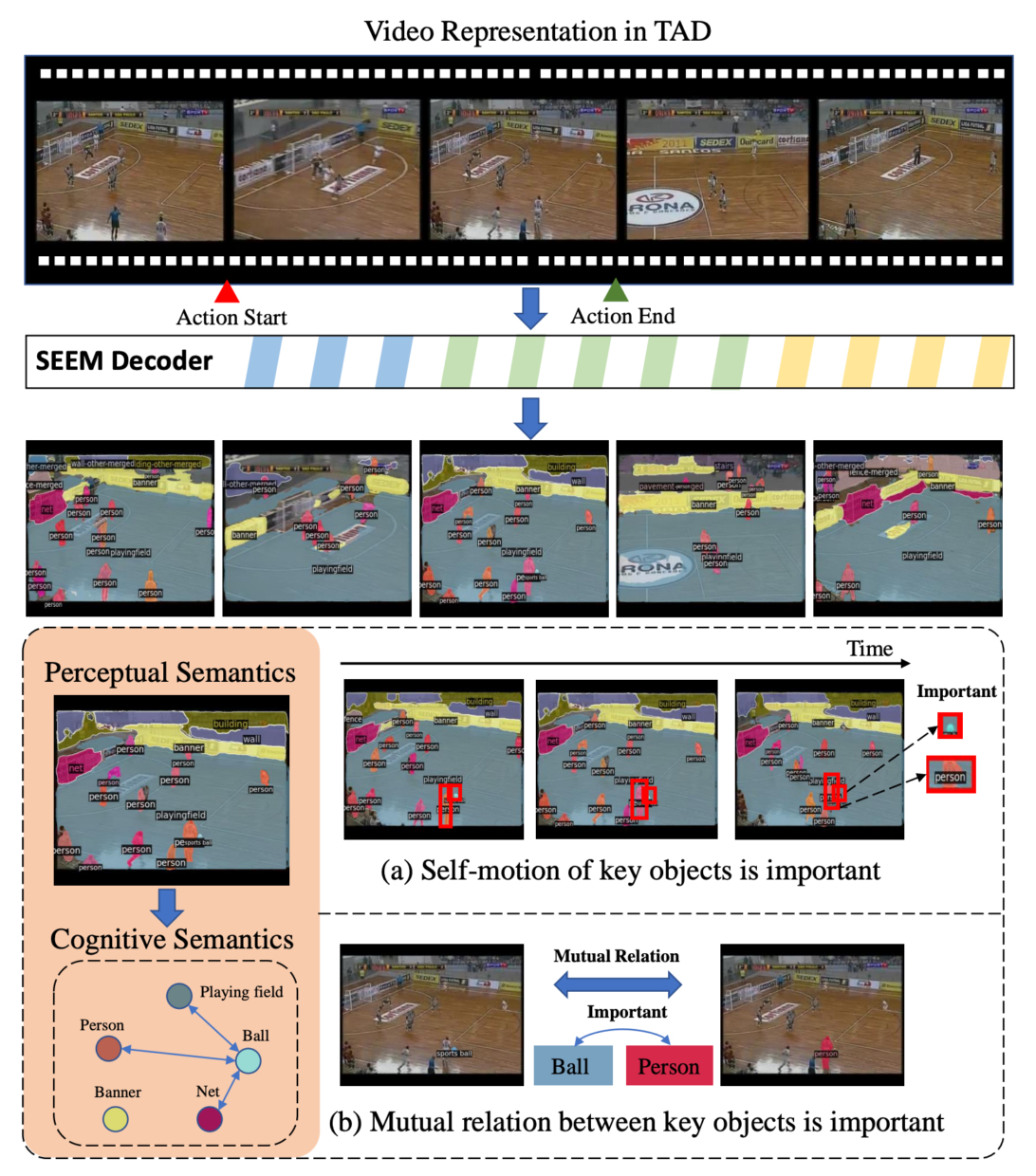
Video embedding is the pivot in Temporal Action Detection (TAD). Once the video embedding can robustly capture the essence of actions and perceive activities in complex scenes, the TAD model can more accurately localize action boundaries. Currently, video embedding is typically based on rule-based pixel convolution or cube-based transformer, wherein structured semantic information is intertwined, leading to the submergence of crucial spatial semantic information, such as the intrinsic motion of key semantic objects and interactions among semantic objects. To address these limitations, it is imperative to explore alternative approaches. With the remarkable performance of general semantic segmentation models in visual representation, we introduce the general segmentation model SEEM into the video embedding paradigm, constructing a semantically structured representation from perceptual semantics to cognitive semantics. To more effectively utilize SEEM for structured video representation, we designed the Semantic Adapter (Sem-Adapter) as a bridge to connect the two models. Firstly, we design a Self-Motion Module (SMM) to pay attention to the self-motion of key semantic regions. Secondly, we propose a Mutual Relation Module (MRM) to construct the interactions between semantic regions. Extensive experiments on ActivityNet-1.3, THUMOS-14 and EPIC-Kitchens-100 reveal that our method significantly outperforms state-of-the-art methods under the same input modality, and our method improves the average mAP from 60.6% to 64.2% on THUMOS-14 with the same backbone. The code is available on https://github.com/shouxiaozixuan/semtad.
Overview
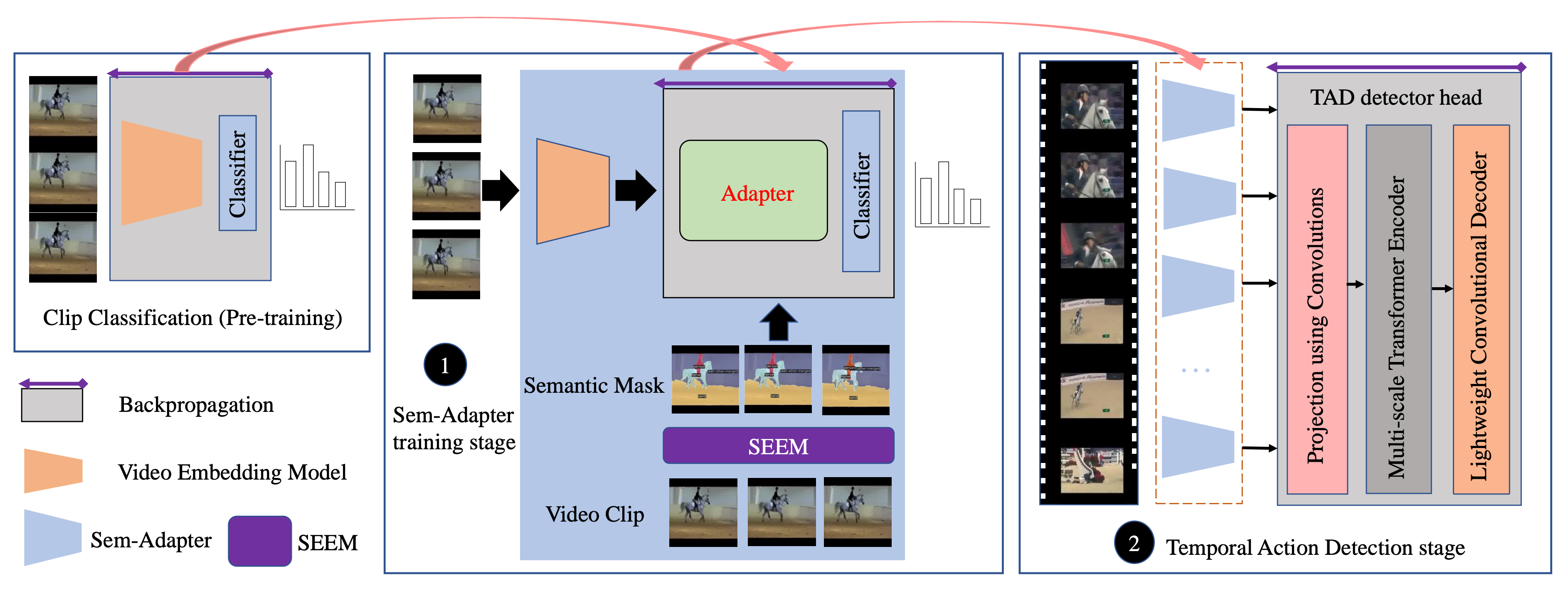
There are two stages in the Sem-TAD: Sem-Adapter training stage and Temporal Action Detection stage. In the Sem-Adapter training stage, Sem-Adapter is trained to establish structured semantic representation of actions. In the action detection stage, TAD detector head is trained to generate action boundaries and labels.
Highlights
1) Sem-Adapter
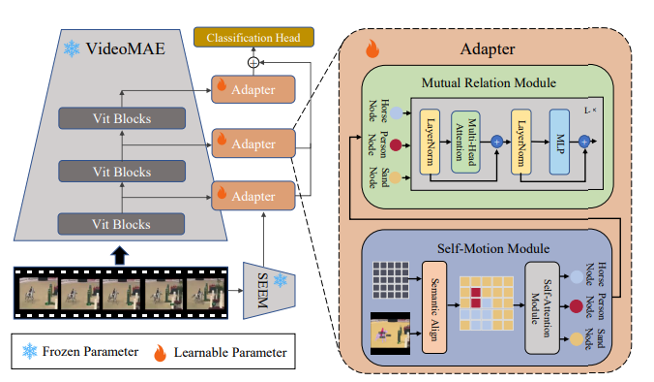
Full fine-tuning a video embedding model or an open-set semantic segmentation model is very costly, requiring a large amount of training data and extremely high computational resources. we design the Sem-Adapter to utilize semantic masks generated by a large semantic segmentation model as prior knowledge to decouple spatial features in the video.
2) Self-Motion Module
We design the Self-Motion Module (SMM) to construct the self-motion of each semantic instance within a video snippet. Firstly, Semantic Align is used to form semantic motion trails in the spatial. Secondly, Semantic Attention Module (SAM) is used to generate the self-motion node with non-local operation.

3) Mutual Relation Module
To further construct the interaction information between self-motion nodes, we proposed the Mutual Relation Module (MRM). MRM builds a transformer-based module, in which the multi-head self-attention (MHSA) computes interactions between self-motion nodes.
Experiments
1) Quantitative results
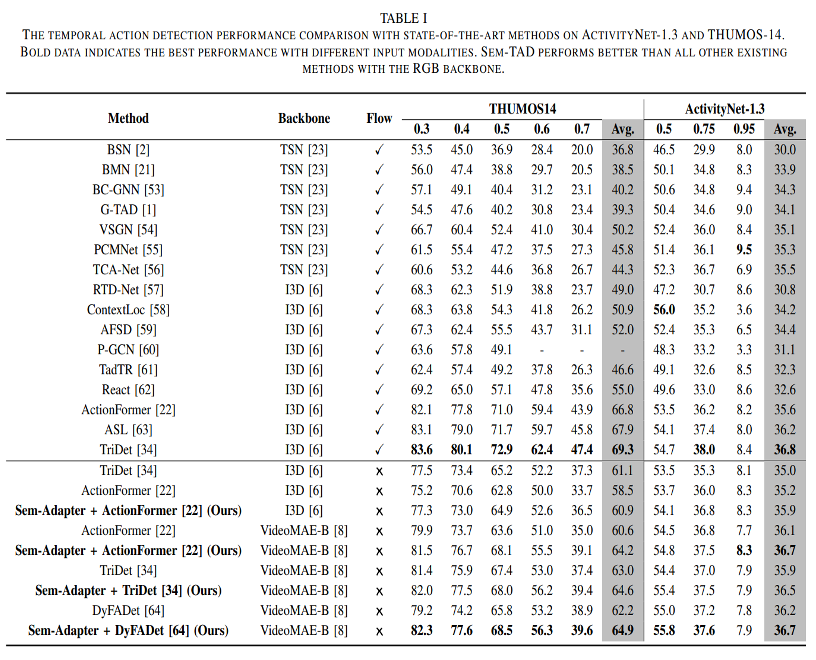
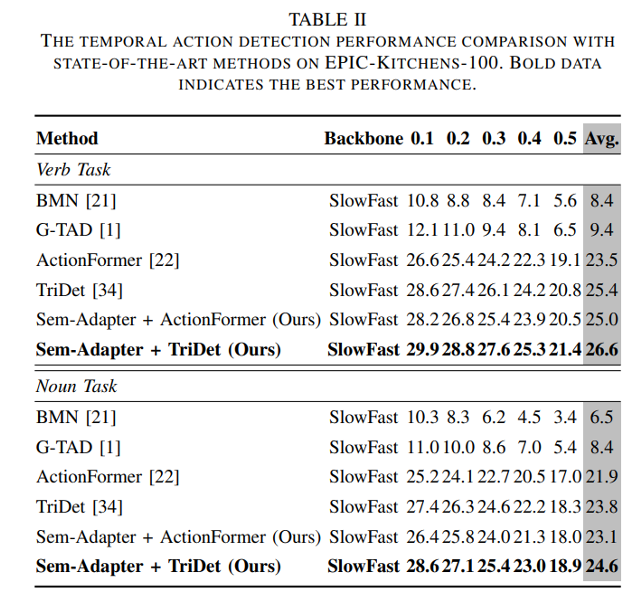
Quantitative experiments are conducted on ActivityNet-1.3, THUMOS-14 and EPIC-Kitchens-100 benchmarks.
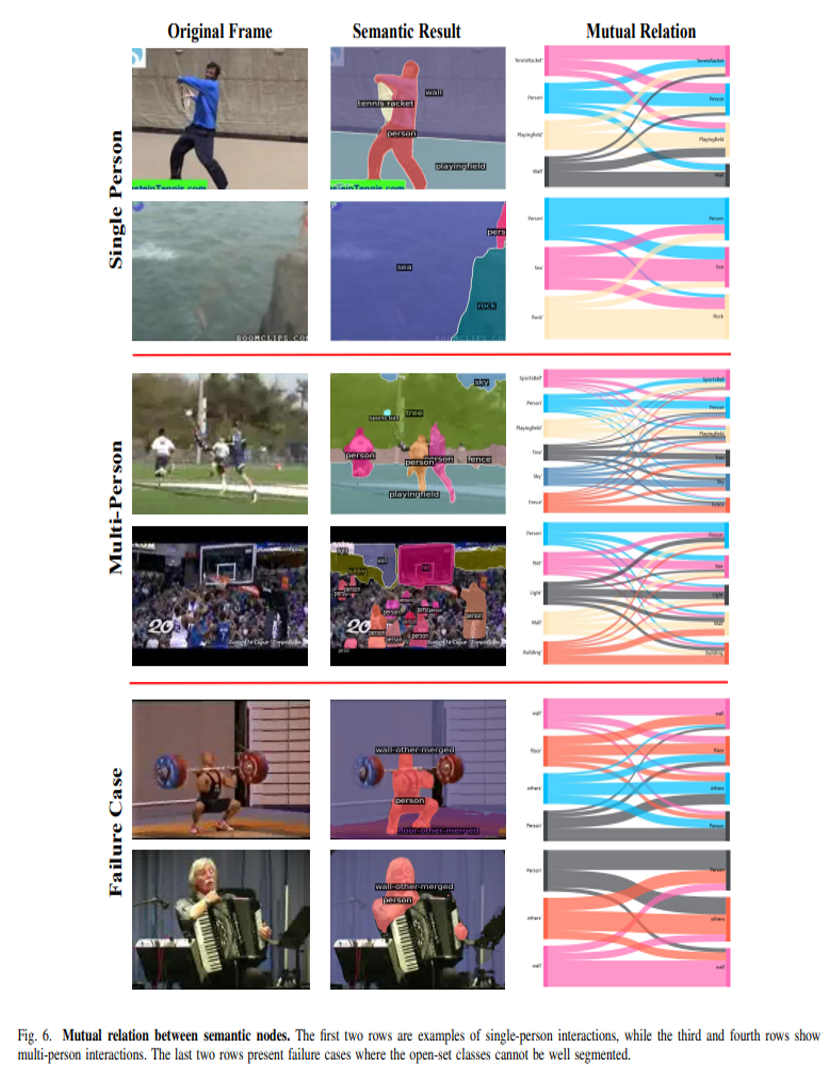
2) Qualitative Results
In order to further demonstrate the construction of interactions between semantic nodes by our MRM, we visualize the interaction weights between semantic nodes.
To clearly demonstrate the action localization results of SemTAD, we show the results of four videos from THUMOS-14.

Citation
@article{zhao2025constructing,
title = {Constructing Semantical Structure by Segmentation Integrated Video Embedding for Temporal Action Detection},
author = {Zhao, Zixuan and Liu, Shuming and Zhao, Chengze and Zhao, Xu},
journal = {IEEE Transactions on Circuits and Systems for Video Technology},
year = {2025},
}