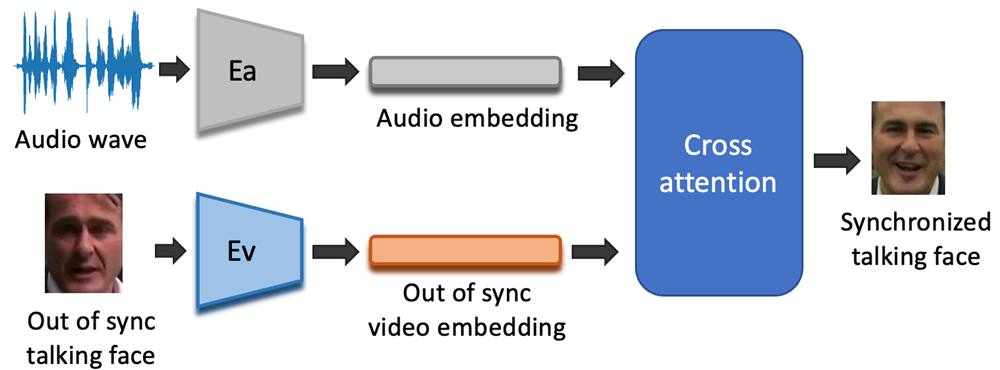
Lip-sync is the task of synchronizing the lip movements of a speaking person with the corresponding audio. It is a critical component of many multimedia applications. Achieving high-quality lip-sync requires accurately modeling the relationship between audio and visual information, as well as the details of human face. To date, existing talking face generation methods can be classified into two types. One type uses intermediate representations such as landmarks to generate lip movements which typically result in a rigid appearance. The other type directly generates images by minimizing the distance between audio and video encodings, but usually suffers from low image resolution and in lack of details.
To address such limitations, we propose a two-stage method which utilizes shift-window based cross-attention mechanism and a vector-quantized Generative Adversarial Network (VQGAN). In the first stage, we use VQGAN to reconstruct fine-detailed images and obtain a latent codebook of the face image. In the second stage, we introduce a novel network utilizing shift-window based cross-attention to generate latent representation of the synchronized image conditioned on audio input. To evaluate the performance, we collect a high-definition facial dataset from news announcers. Experimental results show that our method can generate accurate talking face in different resolutions. Moreover, it can capture more accurate facial details, and achieve a photo-realistic effect especially in high-resolution scenarios.
Copyright © 2024 Computer Vision Laboratory
Address:上海市闵行区东川路800号上海交通大学电院群楼
Zip:200240
备案许可证:沪ICP备05003369