Movement Enhancement toward Multi-Scale Video Feature Representation for Temporal Action Detection
ICCV 2023
Abstract
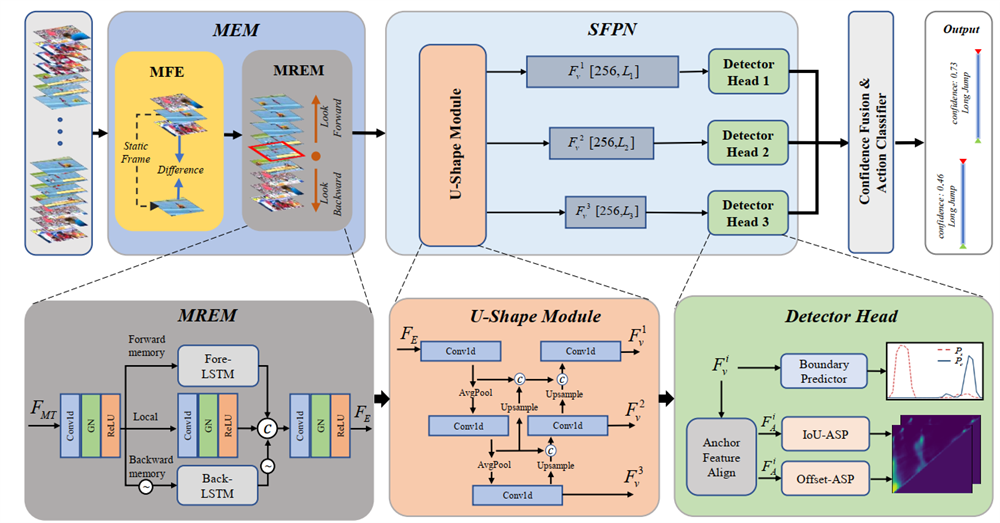
Boundary localization is a challenging problem in Temporal Action Detection (TAD), in which there are two main issues. First, the submergence of movement feature, i.e. the movement information in a snippet is covered by the scene information. Second, the scale of action, that is, the proportion of action segments in the entire video, is considerably variable. In this work, we first design a Movement Enhance Module (MEM) to highlight movement feature for better action location, and then, we propose a Scale Feature Pyramid Network (SFPN) to detect multi-scale actions in videos. For Movement Enhance Module, firstly, Movement Feature Extractor (MFE) is designed to get the movement feature. Secondly, we propose a Multi-Relation Enhance Module (MREM) to grasp valuable information correlation both locally and temporally. For Scale Feature Pyramid Network, we design a U-Shape Module to model different scale actions, moreover, we design the training and inference strategy of different scales, ensuring that each pyramid layer is only responsible for actions at a specific scale. These two innovations are integrated as the Movement Enhance Network (MENet), and extensive experiments conducted on two challenging benchmarks demonstrate its effectiveness. MENet outperforms other representative TAD methods on ActivityNet-1.3 and THUMOS-14.
Highlights
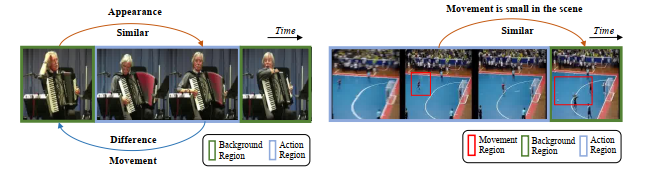
Movement information is covered by the scene information
The first issue, which could be called as movement feature submergence, exists in where either context but not movement itself dominate feature expression, or movement is small in pixel size.
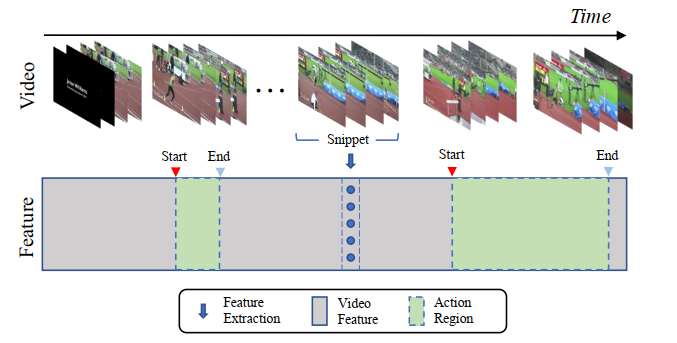
Multi-scale of actions
There are rare features for action segments that account for a small proportion of the entire video, that is the small-scale action, and abundant features for those segments that account for a higher proportion, that is the large-scale action. We contend that there are different action patterns between different scales. Specifically, compared with small-scale action, large-scale action contains more obviously action process (i.e. start phase, action phase and end phase).
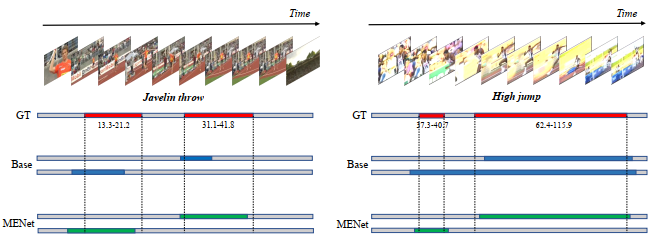
Experiments
Citation
@inproceedings{zhao2023movement,
title = {Movement enhancement toward multi-scale video feature representation for temporal action detection},
author = {Zhao, Zixuan and Wang, Dongqi and Zhao, Xu},
booktitle = {Proceedings of the IEEE/CVF International Conference on Computer Vision},
pages = {13555--13564},
year = {2023}
}