MESA: Matching Everything by Segmenting Anything
CVPR 2024
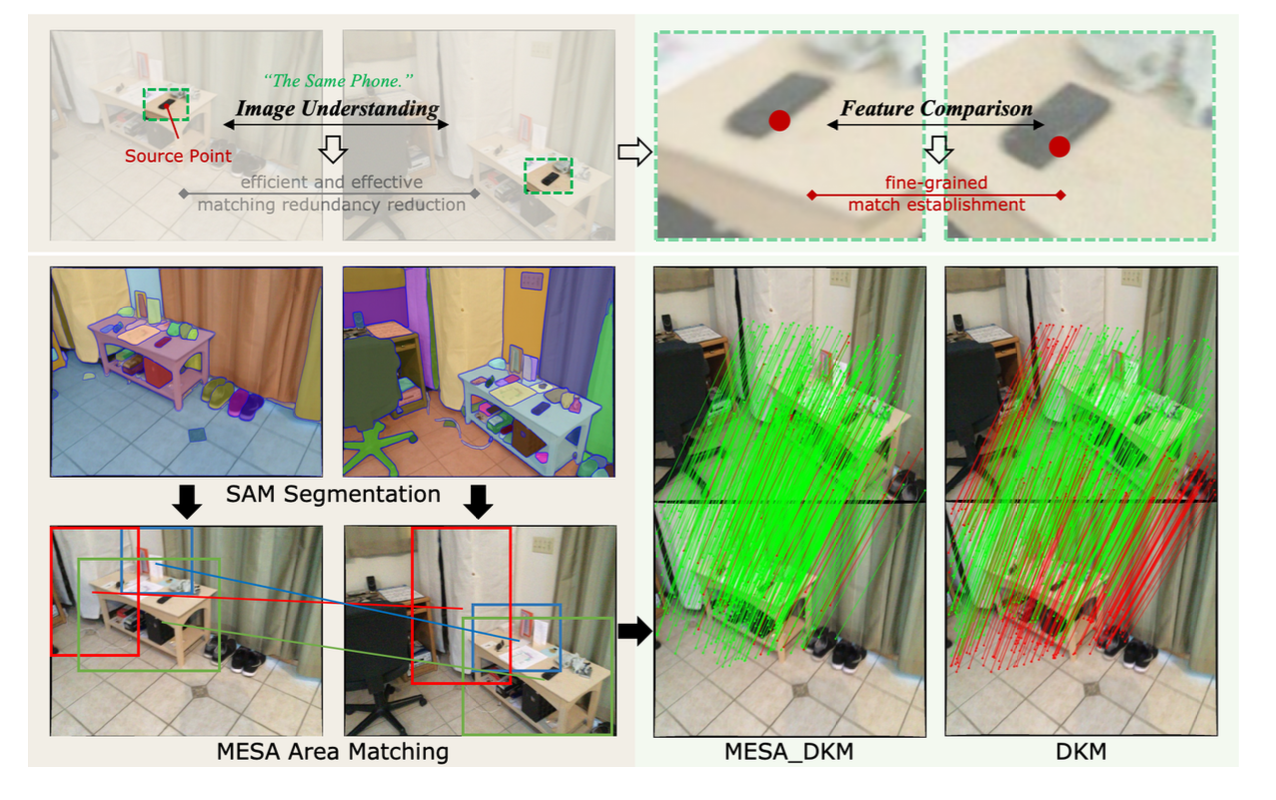
Abstract
Feature matching is a crucial task in the field of computer vision, which involves finding correspondences between images. Previous studies achieve remarkable performance using learning-based feature comparison. However, the pervasive presence of matching redundancy between images gives rise to unnecessary and error-prone computations in these methods, imposing limitations on their accuracy. To address this issue, we propose MESA, a novel approach to establish precise area (or region) matches for efficient matching redundancy reduction. MESA first leverages the advanced image understanding capability of SAM, a state-of-the-art foundation model for image segmentation, to obtain image areas with implicit semantic. Then, a multi-relational graph is proposed to model the spatial structure of these areas and construct their scale hierarchy. Based on graphical models derived from the graph, the area matching is reformulated as an energy minimization task and effectively resolved. Extensive experiments demonstrate that MESA yields substantial precision improvement for multiple point matchers in indoor and outdoor downstream tasks, e.g. +13.61% for DKM in indoor pose estimation.
Video
Highlights
Utilizing SAM to get informative areas in images
Recently, the Segment Anything Model (SAM) has gained notable attention from the research community, as it can comprehend image contents across various domains. We observed that the image understanding from SAM can be leveraged to reduce matching redundancy and propose to utilize SAM to get informative areas in images. As these areas inherently contain implicit semantic information, they can be proper candidates for area matching.

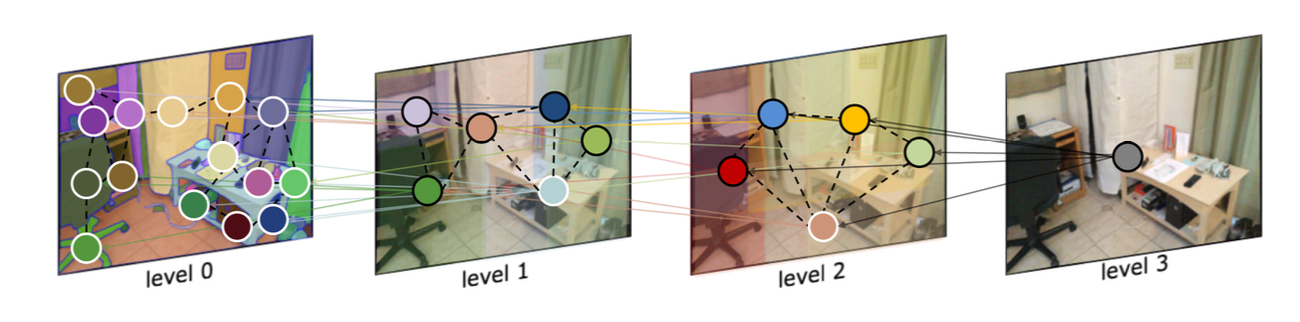
Area Graph Construction
We introduce a multi-relational graph, named Area Graph (AG), to model the spatial structure and scale hierarchy of image areas, contributing to subsequent robust area matching. The construction of AG includes collecting SAM areas as nodes and connecting them by proper edges. However, since SAM inherently produces areas containing complete entity, there are few inclusion relations among areas. Consequently, initial AG lacks the scale hierarchy, which reduces its robustness at scale variations and makes accessing nodes inefficient. To address the issue, we propose to complete the graph by generating parent nodes for every orphan node, thus forming a tree structure in AG.
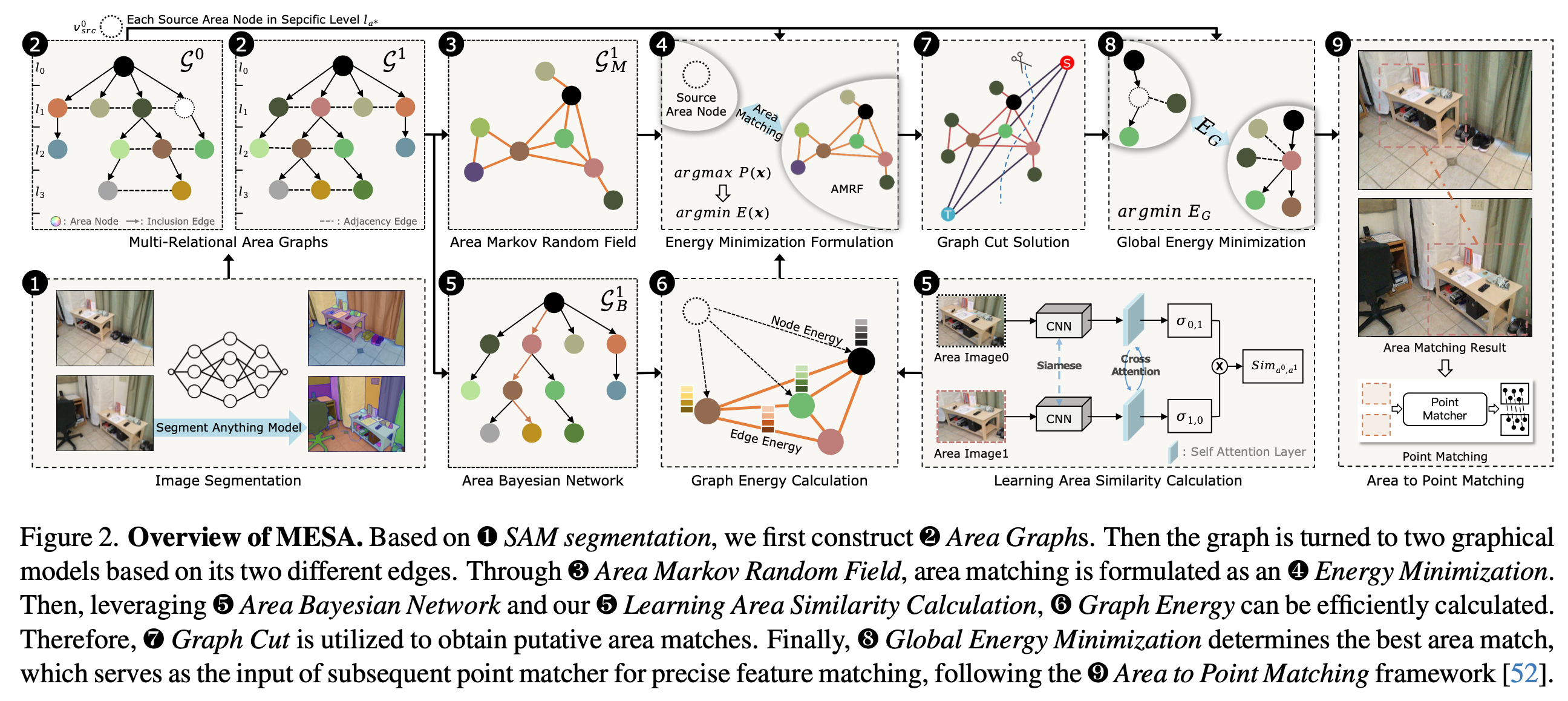
Graphical Area Matching
Firstly, the basis of area matching is the area similarity. We use a learning-based classification model to achieve this. Then, using the similarity and spatial relationship between areas as energy, area matching is naturally treated as an energy minimization on the undirected graph (AMRF) derived from AG. Thus matching status of areas can interact with each other to achieve globally consistent results. Graph-cut is used as it can solve the minimization in polynomial time. As previously stated, the tree structure of AG (ABN) can address the expensive energy calculation issue, by ignoring the children nodes if the similarities of their parents are small. The global energy is designed to choose final matches from graph-cut results based on the structure of two AGs, important to repetitive-robust matching.
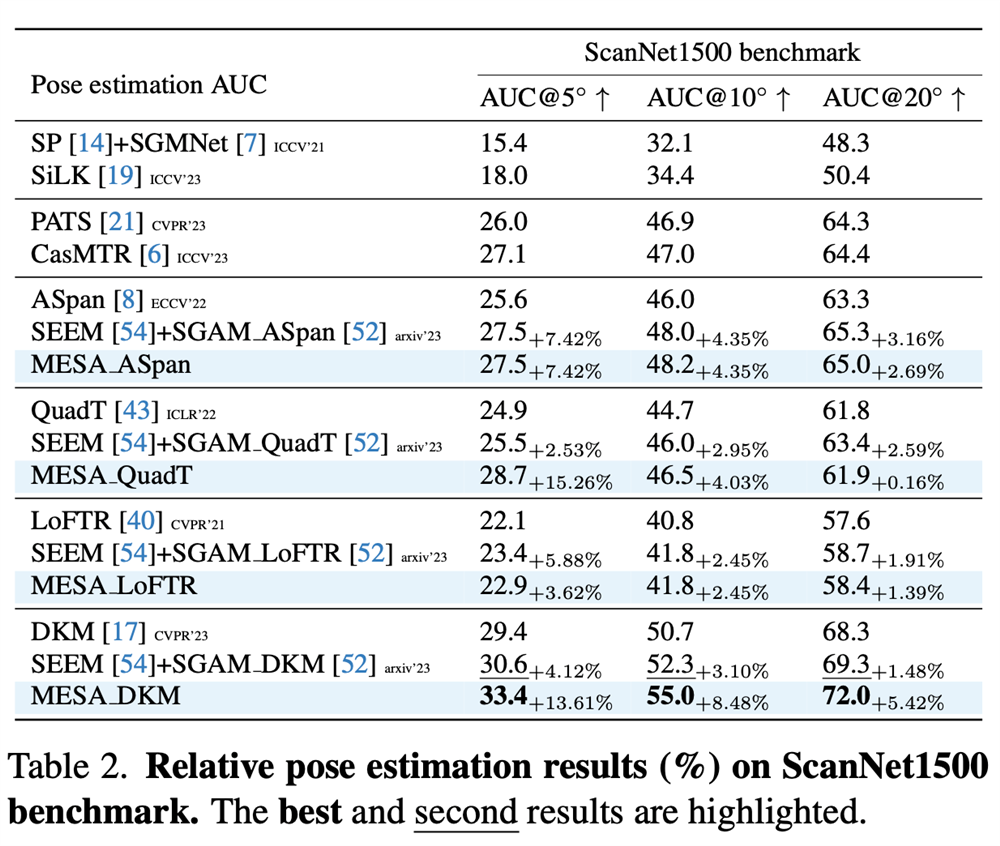
Results
Benchmarks
We conduct experiments on ScanNet1500, MegaDepth1500 and KITTI360 datasets. For these three datasets, MESA achieves significant and consistent improvements for all baselines.
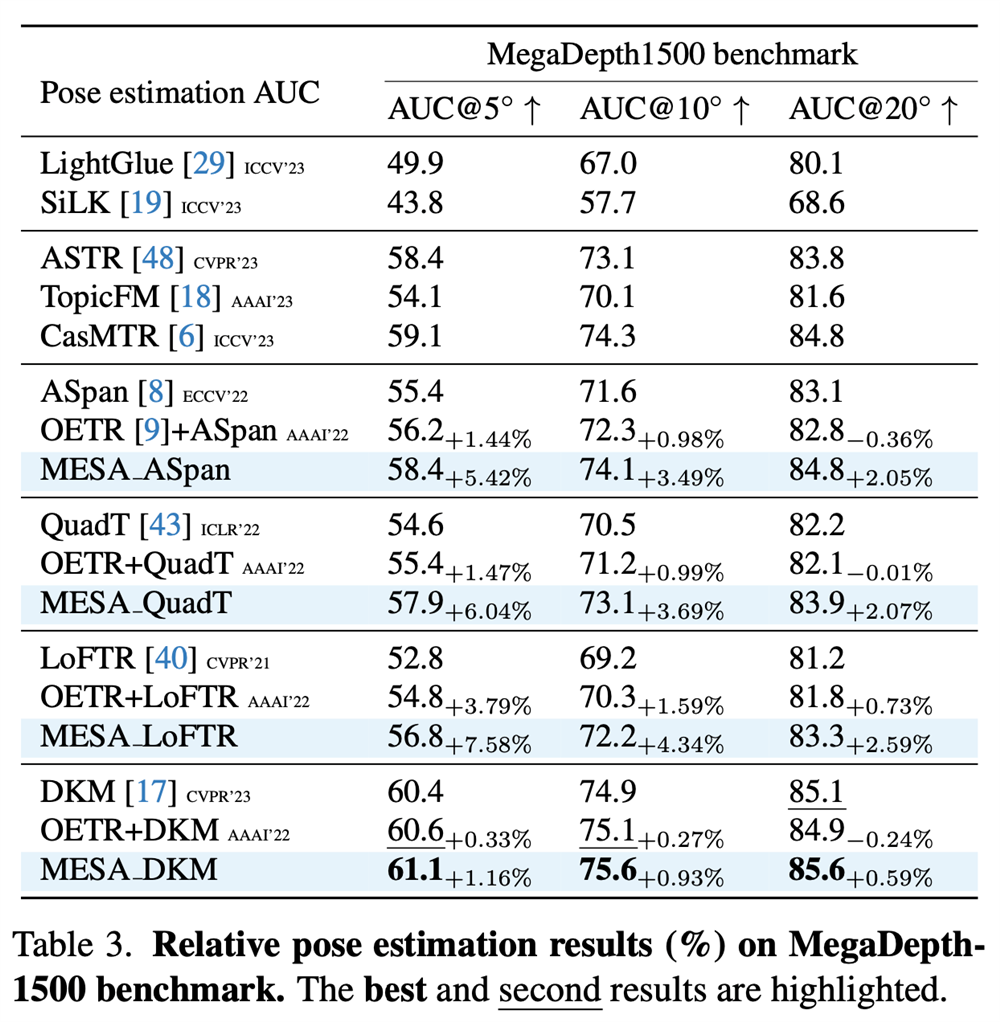
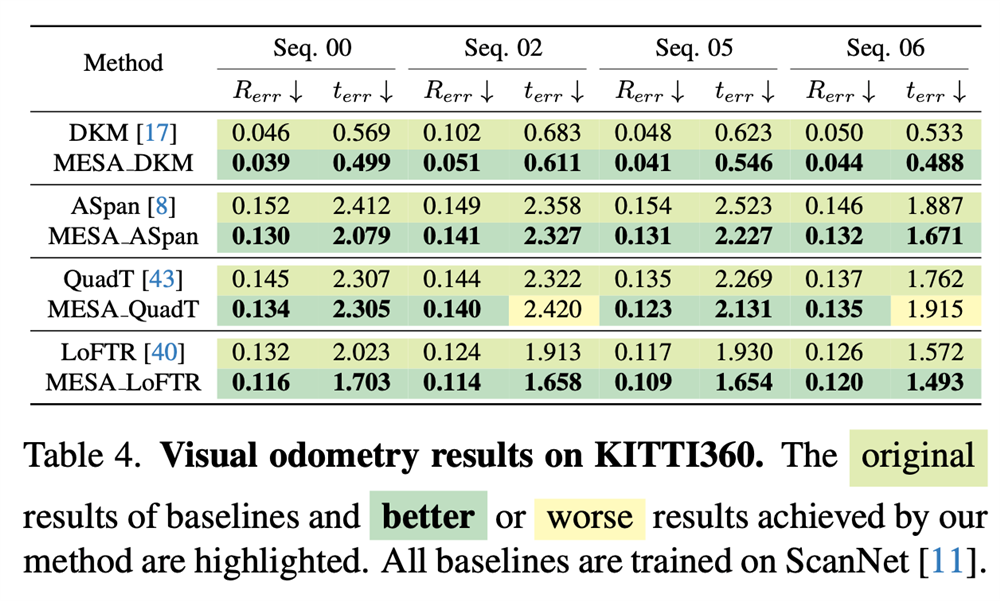
Qualitative Results
Here we provide qualitative results of MESA, including area matching results, results in outdoor and indoor scenes. As we can see that, MESA is able to provide accurate area matches to point matchers, thus leading to precise point matching.



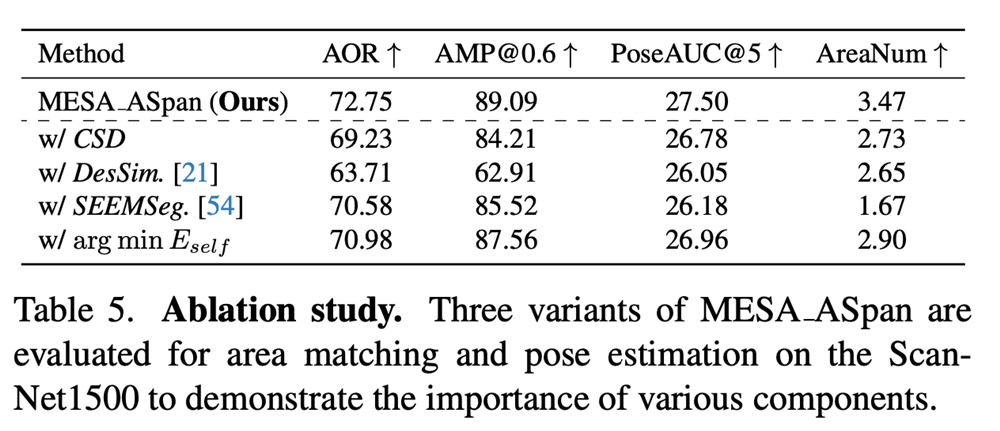
Ablation Study
To evaluate the effectiveness of our design, we conduct a comprehensive ablation study for components of MESA, proving the effectiveness of every component of MESA.
Citation
@inproceedings{zhang2024mesa,
title = {MESA: Matching Everything by Segmenting Anything},
author = {Zhang, Yesheng and Zhao, Xu},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages = {20217--20226},
year = {2024}
}