Semantic-guided Camera Ray Regression for Visual Localization
ICCV 2025
Abstract
This work presents a novel framework for Visual Localization (VL), that is, regressing camera rays from query images to derive camera poses. As an overparameterized representation of the camera pose, camera rays possess superior robustness in optimization. Of particular importance, Camera Ray Regression (CRR) is privacy-preserving, rendering it a viable VL approach for real-world applications. Thus, we introduce DINO-based Multi-Mappers, coined DIMM, to achieve VL by CRR. DIMM utilizes DINO as a scene-agnostic encoder to obtain powerful features from images. To mitigate ambiguity, the features integrate both local and global perception, as well as potential geometric constraint. Then, a scene-specific mapper head regresses camera rays from these features. It incorporates a semantic attention module for soft fusion of multiple mappers, utilizing the rich semantic information in DINO features. In extensive experiments on both indoor and outdoor datasets, our methods showcase impressive performance, revealing a promising direction for advancements in VL.
Highlights
Introducing Camera Ray Regression in Visual Localization
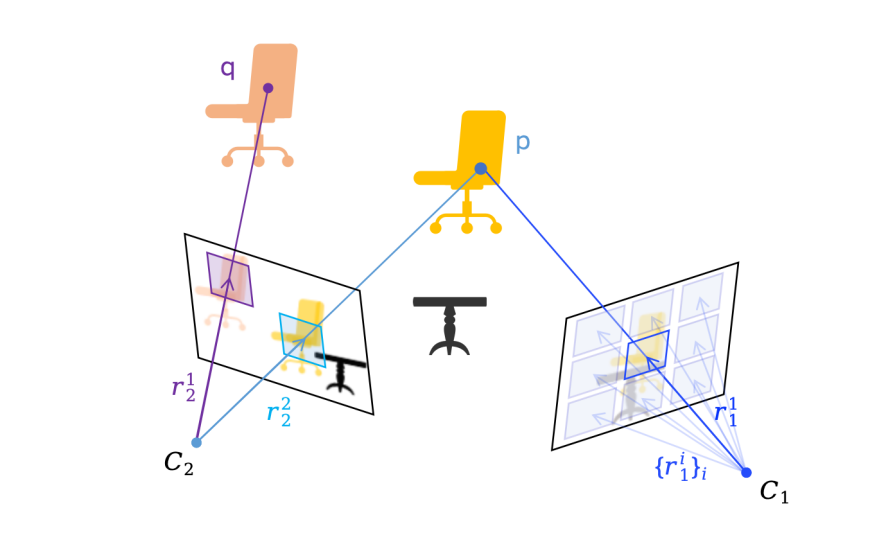
Based on deep learning, visual localization are currently formulated as two types: direct regression of camera pose or prediction of 2D-3D point matching. The former is easily affected by noise due to the compactness of the pose representation, resulting in suboptimal results. The latter, however, relies on scene-specific hyperparameter adjustments in practice due to the lack of optimization boundaries of 3D points. Meanwhile, since 3D points directly correspond to scene geometric information, there is a risk of privacy leakage. Therefore, a superior modeling method to achieve precise, robust, and privacy-protected visual localization is highly desirable. Recently, a novel camera pose representation, camera ray, has attracted much attention in various 3D vision tasks. As an overparameterized representation of camera pose, the camera ray is consistent with image patch features in dimension, which is conducive to network learning. Also, the ray error is more robust than 3D points in optimization. At the same time, it is very difficult to recover scene structure from camera rays, which brings better privacy protection. Inspired by these factors, we have first introduced camera rays into the visual localization task.
DINO-based Patch-level Feature Input
The camera ray and image patch features naturally correspond in dimension, thus each image block feature can correspond to a camera ray. Based on this, we use the current advanced image feature extractor, DINOv2 feature (Patch Token), as the basis for camera ray regression. Noting that image block features have local ambiguities, we also extend the summary features output by DINO (CLS Token) to the patch level to alleviate the ambiguity problem. To enhance the geometric perception of the model, we concat the patch center coordinates (XY Token) in the form of Fourier encoding with the aformentioned patch features, obtaining the final input features for the camera ray regression model.
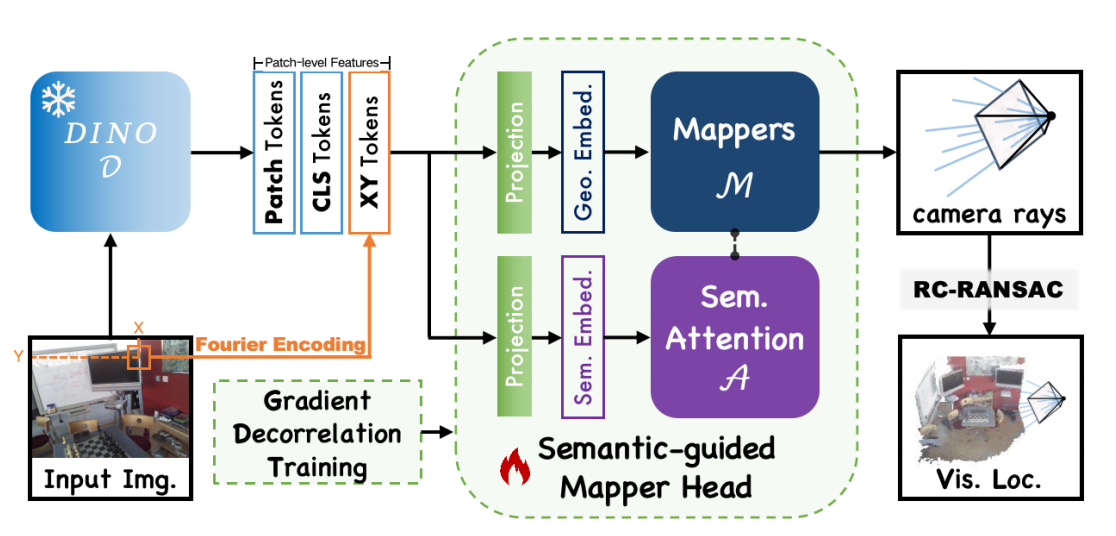
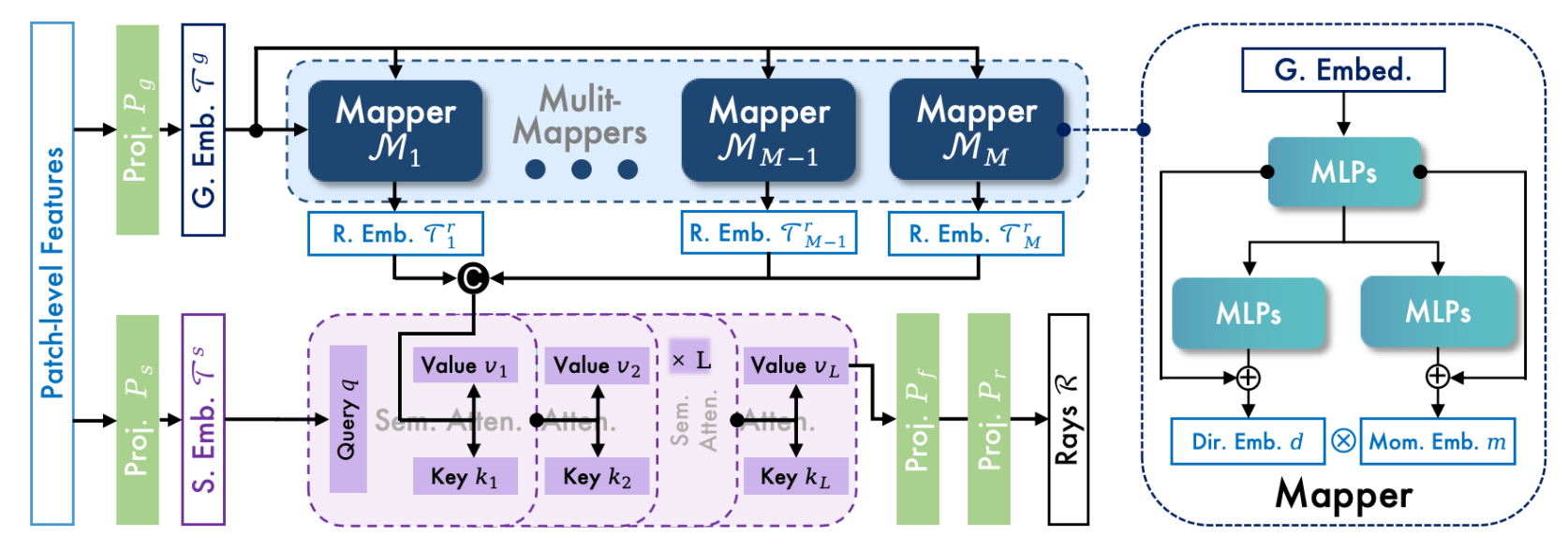
Semantic-guided Multi-Mapper Fusion
Current visual localization methods commonly use multi-layer perceptrons (MLP) as the mapping layer from image features to pose parameters (termed as Mapper). However, the capacity of a single MLP is limited, and its accuracy is also restricted when facing larger-scale scenes. Therefore, we adopt multiple MLP mappers and fuse their outputs to obtain better results. Noticing that the DINO features we input contain rich semantic information, we design a semantic attention module to utilize semantic information to fuse the results of multiple MLP Mappers. First, we use two projection layers to extract semantic embedding and geometric embedding from the DINO-based input features. Then, the geometric features are mapped to multiple independent ray embeddings by MLP Mappers. Next, these ray embeddings interact with the semantic embedding in the attention module to obtain the fused ray embeddings. Finally, a single MLP projection layer is used to achieve the camera ray parameters.
Ray-level RANSAC Pose Estimation
The camera ray parameters regressed from our model inevitably contain noise. Therefore, the camera pose directly solved from the camera rays by the least squares method is inaccurate. To further reduce the impact of noise, we apply the Random Sample Consensus algorithm (RANSAC) to estimate camera pose from rays. Moreover, since the rays decouple the camera rotation and translation, we propose two RANSAC processes. First, we solve the rotation parameters by a RANSAC process. Then, the rays can be corrected by the rotation. The translation parameters can be solved by another RANSAC process from the corrected rays. Finally, the camera pose is obtained by combining the rotation and translation parameters.
Experiments
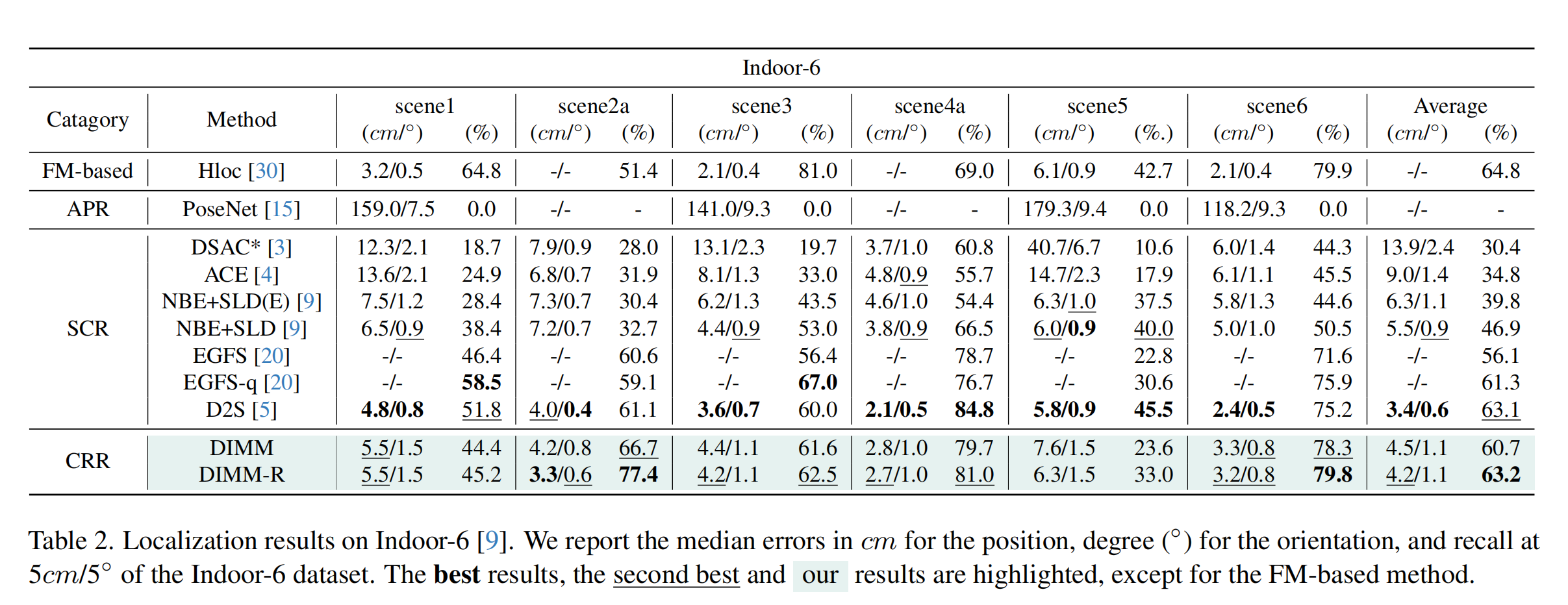
6 Scenes Dataset
We conduct experiments on the 6 Scenes dataset, which is a widely used benchmark for visual localization. The dataset consists of six indoor scenes, each with a set of images and corresponding ground truth camera poses. We evaluate our method on this dataset to demonstrate its effectiveness in visual localization tasks.
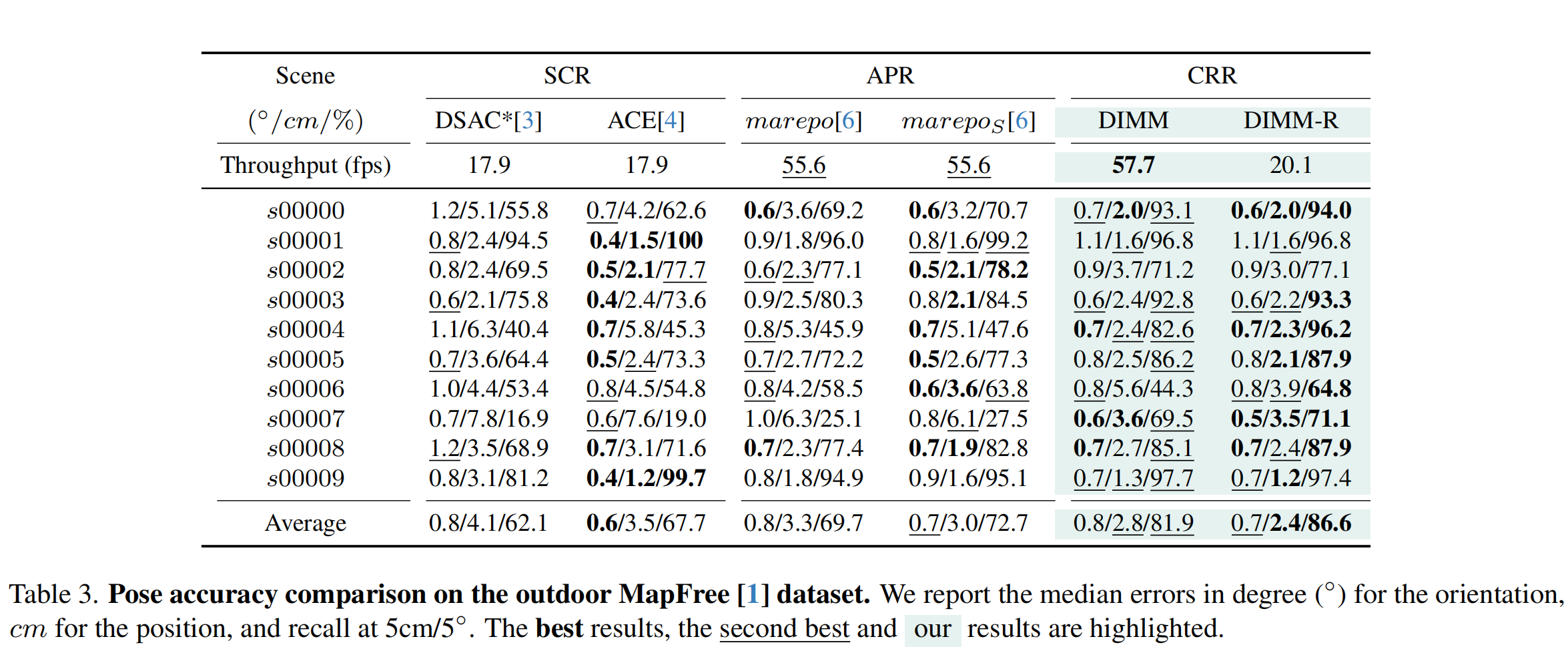
MapFree Dataset
We also evaluate our method on the MapFree dataset, which is a challenging outdoor dataset for visual localization. The dataset contains images captured in various outdoor environments, and we assess the performance of our method in these scenarios.
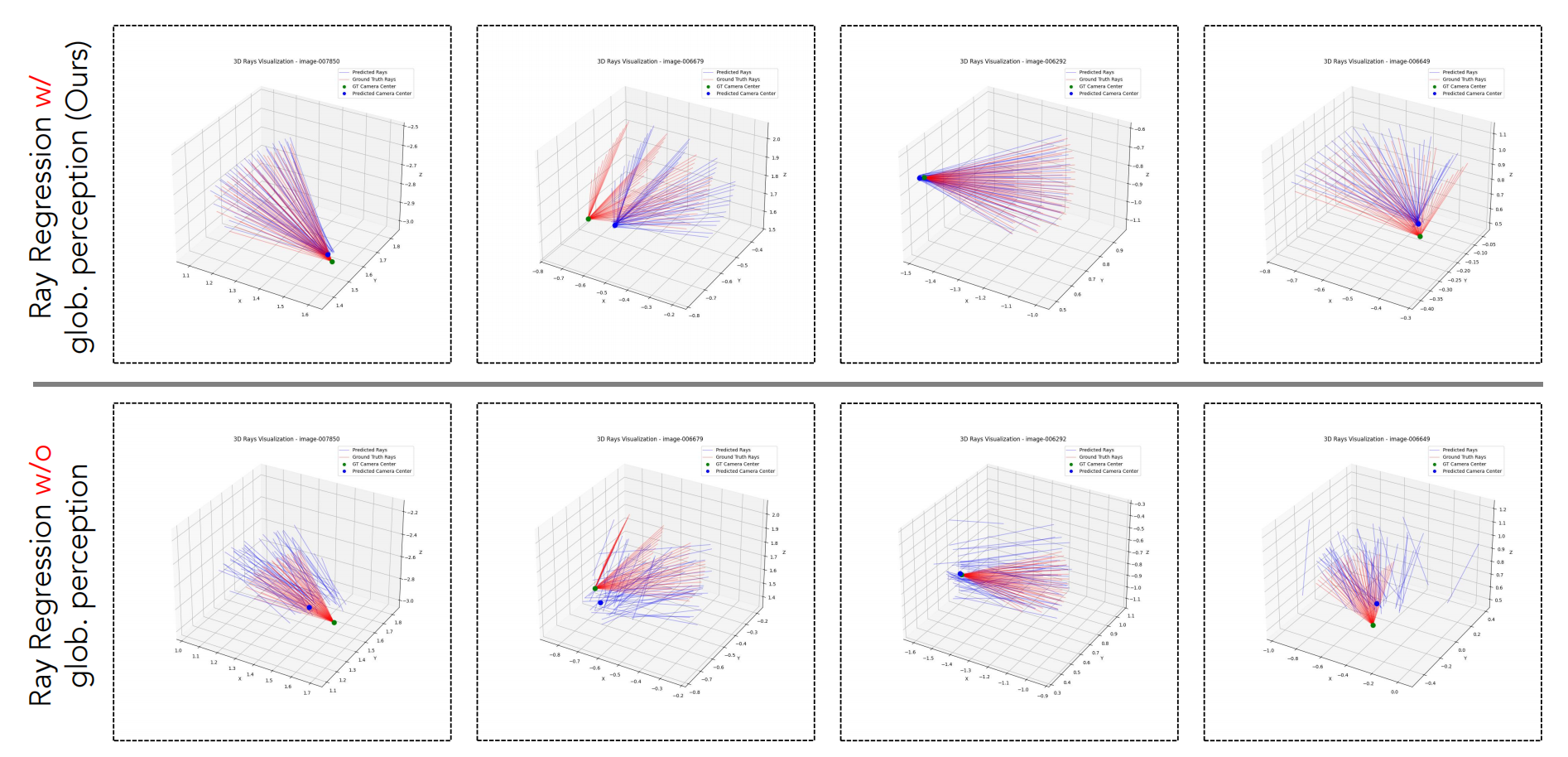
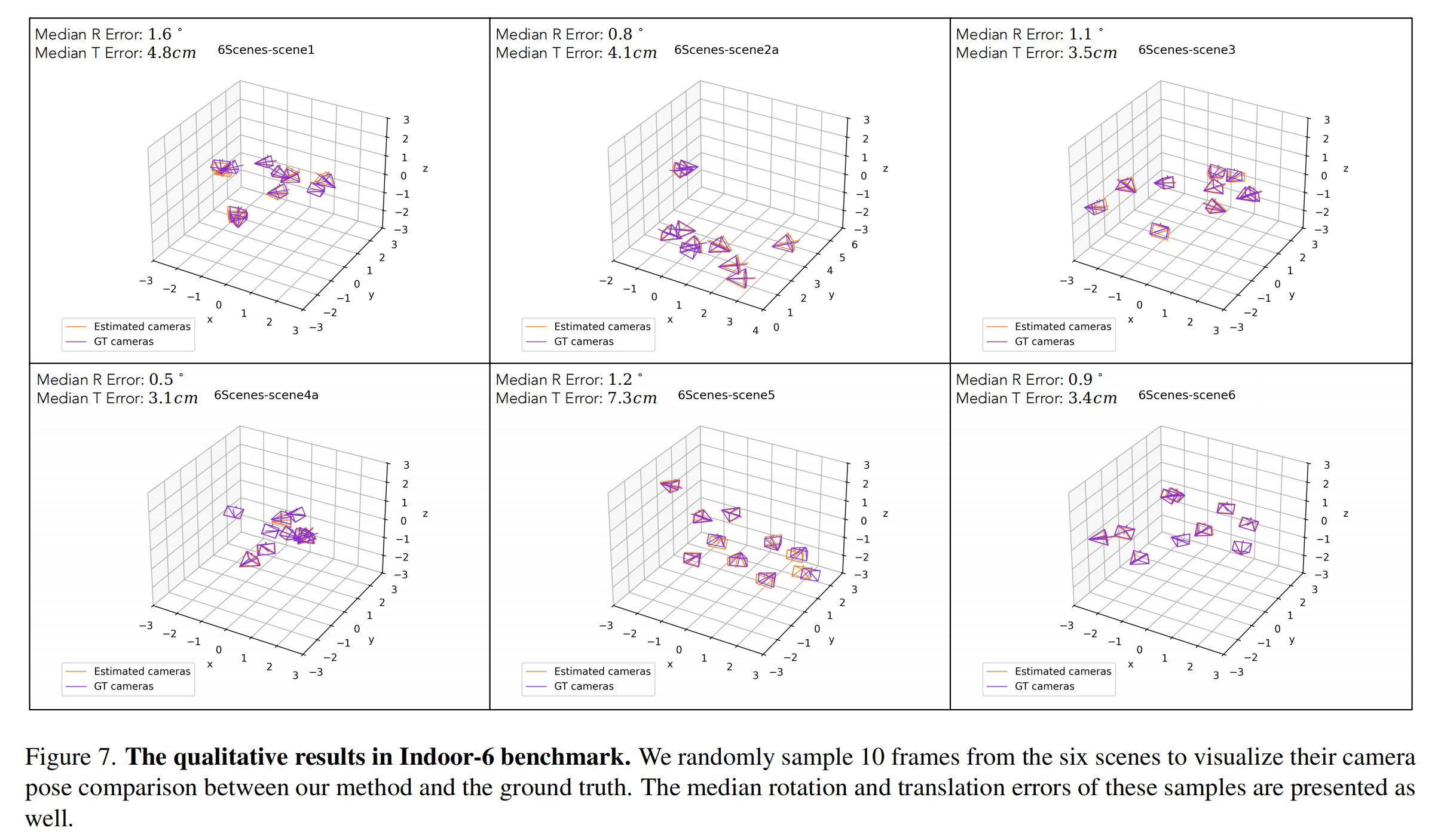
Qualitative Results
We also provide qualitative results to showcase the effectiveness of our method in visual localization.
Citation
@InProceedings{zhang2025semantic,
author = {Zhang, Yesheng and Zhao, Xu},
title = {Semantic-guided Camera Ray Regression for Visual Localization},
booktitle = {Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)},
month = {October},
year = {2025},
pages = {25639-25648}
}