口型同步是将说话人的嘴唇动作与相应的音频同步的任务。它是许多多媒体应用程序的重要组成部分。实现高质量的口型同步需要准确地模拟音频和视觉信息之间的关系,以及人脸的细节。迄今为止,现有的说话人脸生成方法可以分为两种类型。一种类型使用中间表示(例如人脸关键点)来生成通常会导致僵硬外观的嘴唇运动。另一种类型通过最小化音频和视频编码之间的距离直接生成图像,但通常存在图像分辨率低且缺乏细节的问题。
为了解决上述问题,我们提出了一种两阶段方法,该方法利用基于移位窗口的交叉注意机制和矢量量化变分自编码生成对抗网络(VQGAN)。在第一阶段,我们使用 VQGAN 重建精细图像并获得人脸图像的潜在编码字典。在第二阶段,我们引入了一种新颖的网络,利用基于移位窗口的交叉注意力来生成以音频输入为条件的同步图像的潜在表示。为了评估性能,我们从新闻播音员那里收集了高清面部数据集。实验结果表明,我们的方法可以在不同分辨率下生成准确的说话人脸。此外,它可以捕捉到更准确的面部细节,尤其是在高分辨率场景下,可以达到照片般逼真的效果。
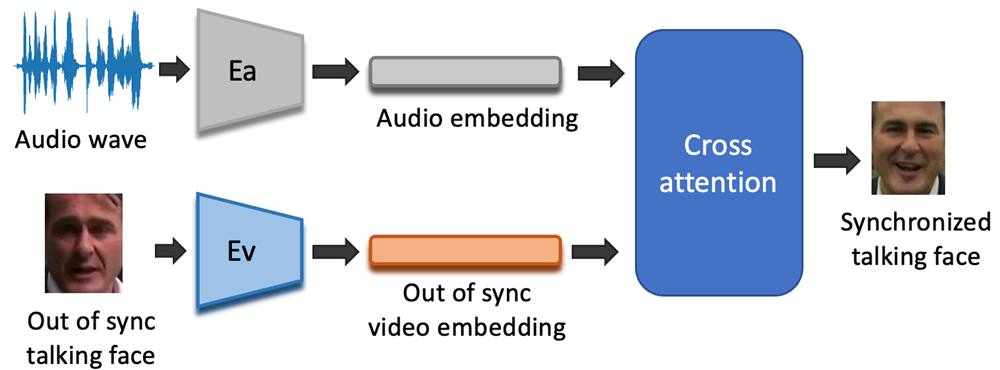
图1. 口型同步算法流程示意图