RSB-Pose: Robust Short-Baseline Binocular 3D Human Pose Estimation with Occlusion Handling
IEEE TIP 2024
Abstract
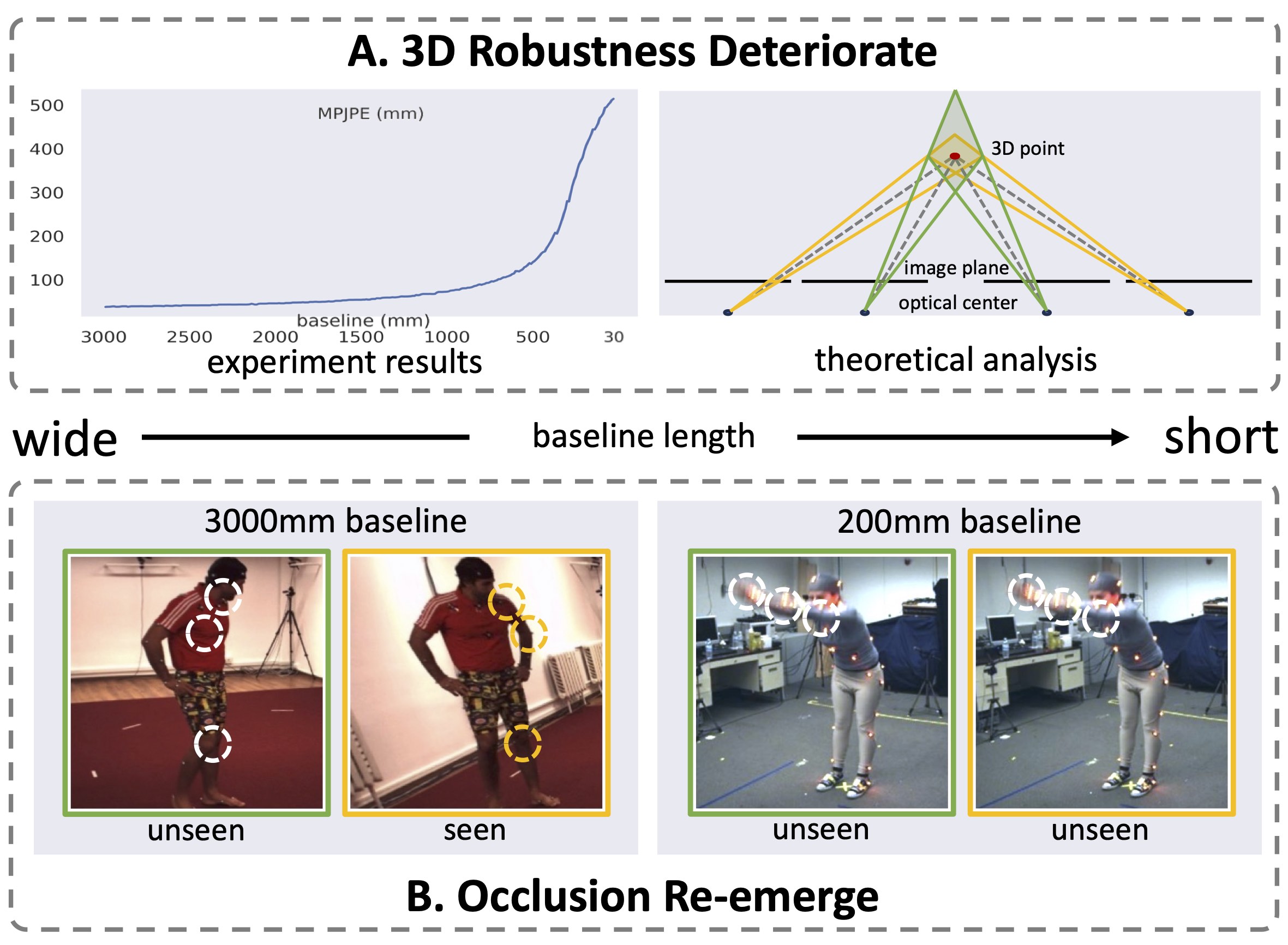
In the domain of 3D Human Pose Estimation, which finds widespread daily applications, the requirement for convenient acquisition equipment continues to grow. To satisfy this demand, we focus on a short-baseline binocular setup that offers both portability and a geometric measurement capability that significantly reduces depth ambiguity. However, as the binocular baseline shortens, two serious challenges emerge: first, the robustness of 3D reconstruction against 2D errors deteriorates; second, occlusion reoccurs frequently due to the limited visual differences between two views. To address the first challenge, we propose the Stereo Co-Keypoints Estimation module to improve the view consistency of 2D keypoints and enhance the 3D robustness. In this module, the disparity is utilized to represent the correspondence of binocular 2D points, and the Stereo Volume Feature (SVF) is introduced to contain binocular features across different disparities. Through the regression of SVF, two-view 2D keypoints are simultaneously estimated in a collaborative way which restricts their view consistency. Furthermore, to deal with occlusions, a Pre-trained Pose Transformer module is introduced. Through this module, 3D poses are refined by perceiving pose coherence, a representation of joint correlations. This perception is injected by the Pose Transformer network and learned through a pre-training task that recovers iterative masked joints. Comprehensive experiments on H36M and MHAD datasets validate the effectiveness of our approach in the short-baseline binocular 3D Human Pose Estimation and occlusion handling.
Overview
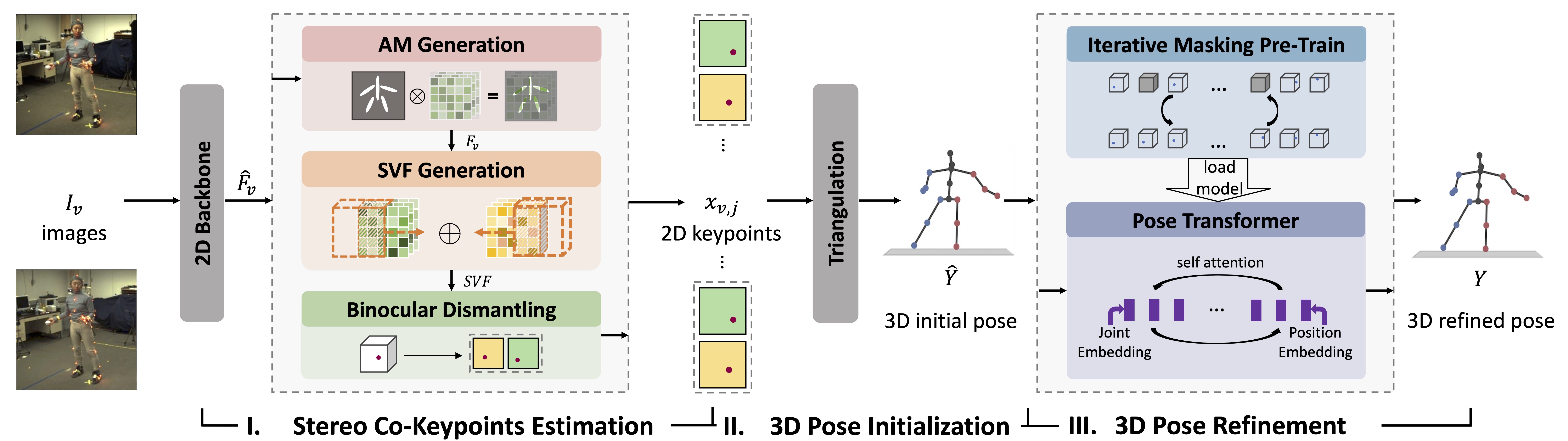
The binocular images are firstly encoded by a 2D backbone and then processed through three main steps: I. Stereo Co-Keypoints Generation: Two-view features are concatenated in the Stereo Volume Feature (SVF), facilitating the simultaneous regression of 2D binocular keypoints and ensuring their view consistency; II. 3D Pose Initialization: Triangulation is utilized to reconstruct the initial 3D pose; III. 3D Pose PPT Refinement: Pose coherence is perceived by the Pose Transformer through pre-training and then injected into the refined 3D pose.
Highlights
1) Stereo Co-Keypoints Estimation
We agree that the likelihood of a pixel in one view being the keypoint should be jointly determined by its corresponding pixel in another view. But the central challenge lies in identifying this corresponding pixel. Here, we utilize disparity to describe the corresponding relationship and propose Stereo Co-Keypoints Estimation (SCE) module to simultaneously estimate binocular keypoints. The framework of SCE includes: I. Attention Mask Generation, to focus initial features on the huaman body of interest; II. Stereo Volume Feature (SVF) Generation, to consider both binocular views simultaneously and form as a 4D feature volume; III. 2D Binocular Dismantling, to solve binocular 2D keypoints from co-keypoints regressed from SVF.
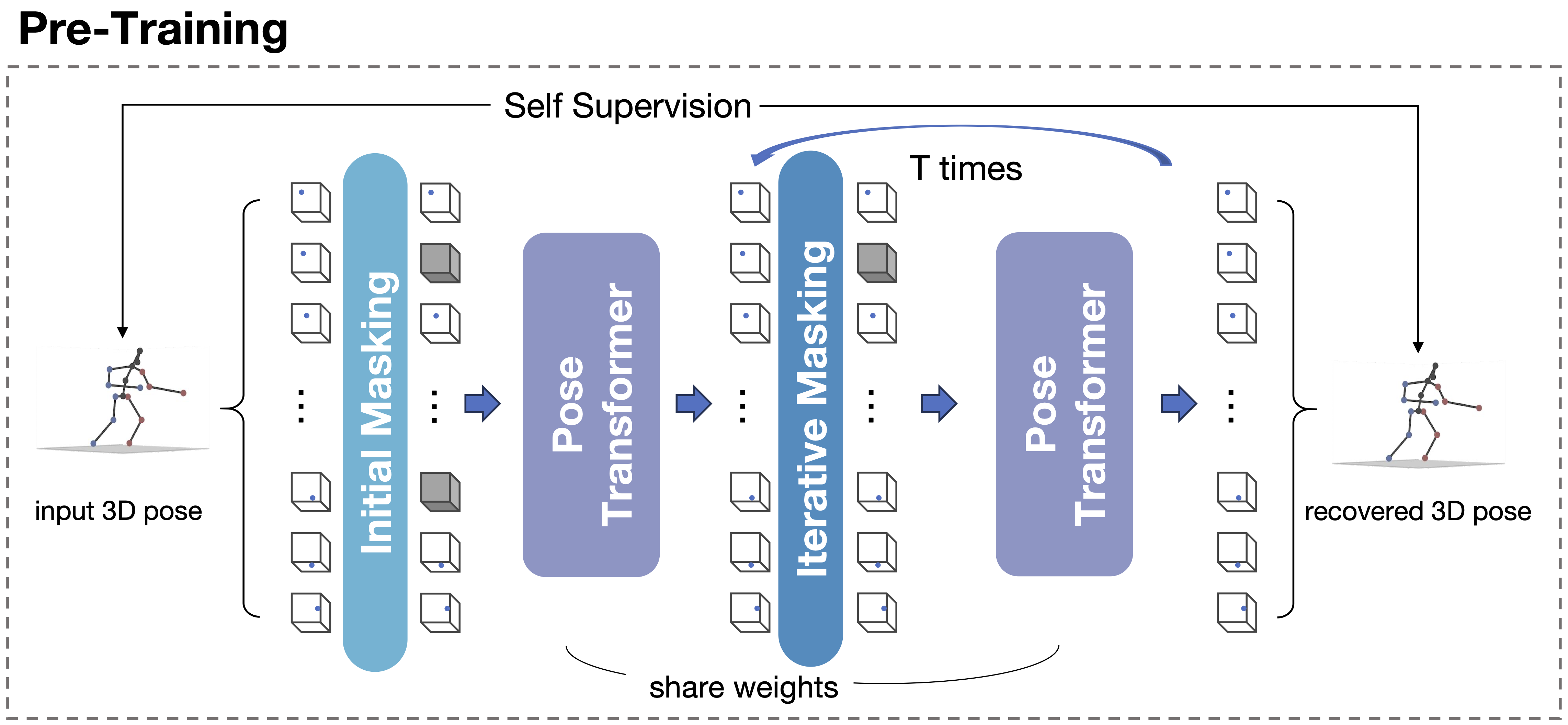
2) Pre-trained Pose Transformer
To capture the coherence within the 3D pose, we propose a self-supervised task to pre-train the Pose Transformer, recovering masked keypoints within the entire 3D pose. And to fill the gap between the groundtruth input in pre-training and the estimated input during inference, an iterative recovery strategy is employed. At the end of each iteration, we only retain the top-K confident recovered 3D points.
Experiments
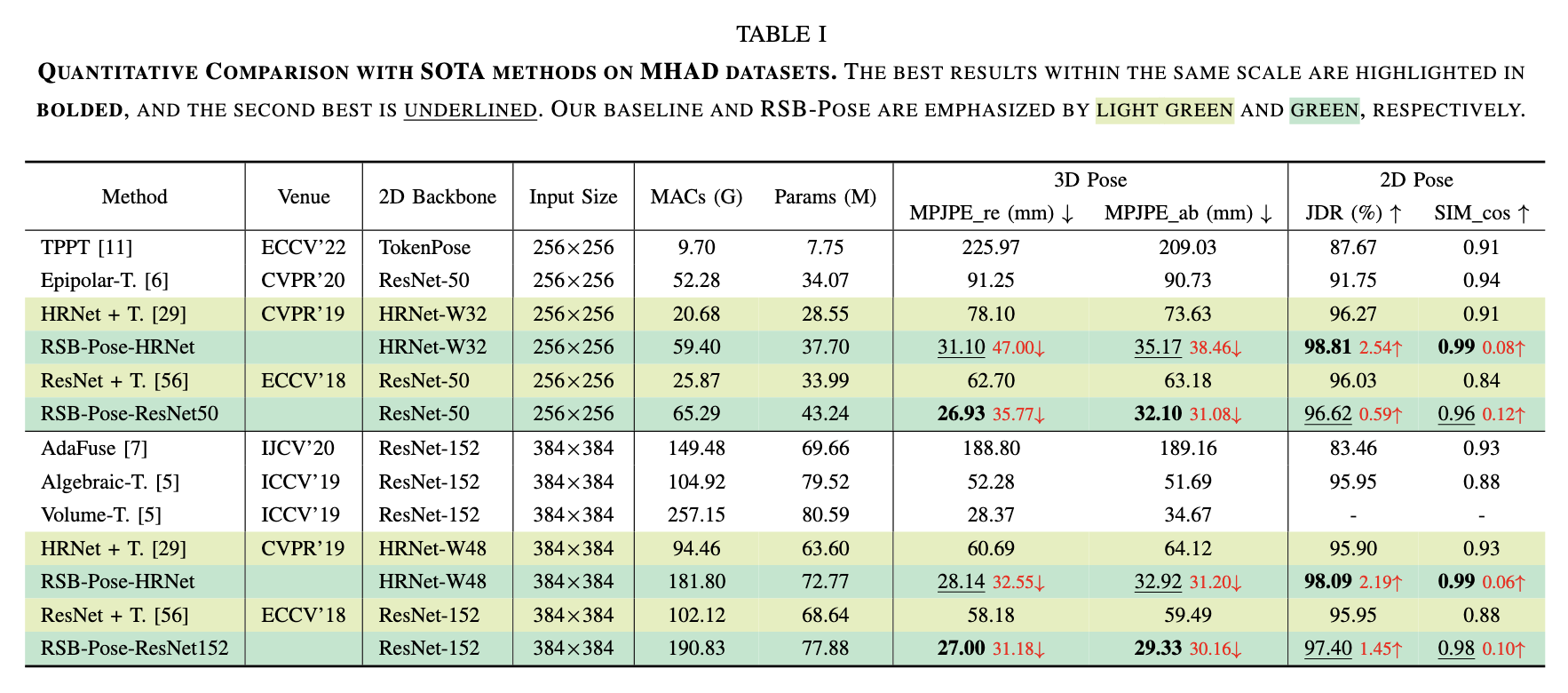
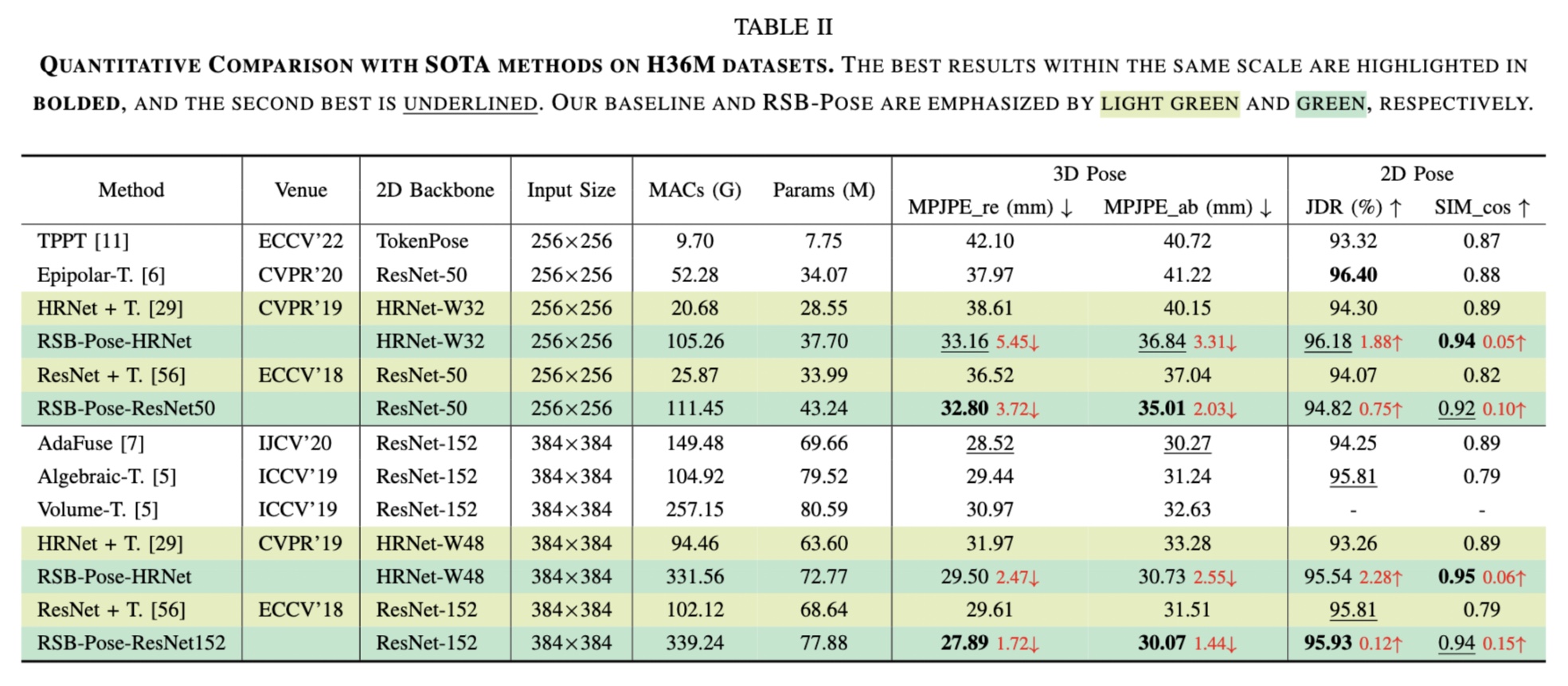
1) Quantitative results
Quantitative experiments are conducted on two benchmarks: 1) the short-baseline binocular benchmark, MHAD Berkeley dataset, and 2) the wide-baseline benchmark, H36M dataset.
2) Qualitative Results
We further visualize some 3D poses generated from our RSB-Pose, Algebraic-T., and Volume-T. respectively. RSB-Pose excels in estimating the limb joints, which are the most flexible, including the elbow, wrist, knee, ankle, and head. Even in cases of heavy occlusion in both views, RSB-Pose provides superior and plausible results.

Citation
@article{wan2023rsb,
title = {RSB-Pose: Robust Short-Baseline Binocular 3D Human Pose Estimation with Occlusion Handling},
author = {Wan, Xiaoyue and Chen, Zhuo and Zhao, Xu},
journal = {IEEE Transactions on Image Processing},
year = {2024},
}